Publications
2023
-
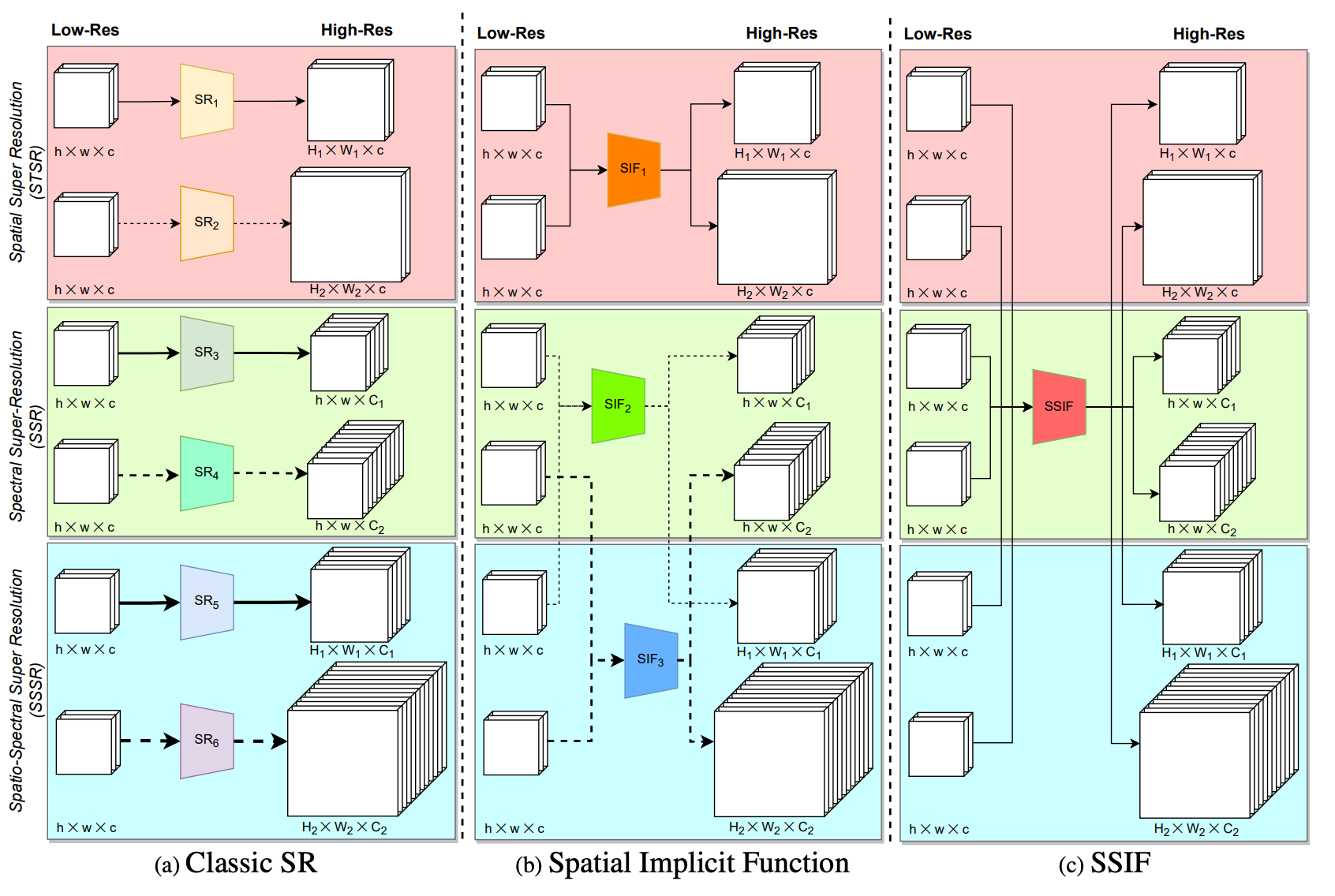 ARXIVSSIF: Learning Continuous Image Representation for Spatial-Spectral Super-ResolutionGengchen Mai, Ni Lao, Weiwei Sun, Yuchi Ma, Jiaming Song, Chenlin Meng, Hongxu Ma, Jinmeng Rao, Ziyuan Li, and Stefano ErmonarXiv preprint arXiv:2310.00413, 2023
ARXIVSSIF: Learning Continuous Image Representation for Spatial-Spectral Super-ResolutionGengchen Mai, Ni Lao, Weiwei Sun, Yuchi Ma, Jiaming Song, Chenlin Meng, Hongxu Ma, Jinmeng Rao, Ziyuan Li, and Stefano ErmonarXiv preprint arXiv:2310.00413, 2023Existing digital sensors capture images at fixed spatial and spectral resolutions (e.g., RGB, multispectral, and hyperspectral images), and each combination requires bespoke machine learning models. Neural Implicit Functions partially overcome the spatial resolution challenge by representing an image in a resolution-independent way. However, they still operate at fixed, pre-defined spectral resolutions. To address this challenge, we propose Spatial-Spectral Implicit Function (SSIF), a neural implicit model that represents an image as a function of both continuous pixel coordinates in the spatial domain and continuous wavelengths in the spectral domain. We empirically demonstrate the effectiveness of SSIF on two challenging spatio-spectral super-resolution benchmarks. We observe that SSIF consistently outperforms state-of-the-art baselines even when the baselines are allowed to train separate models at each spectral resolution. We show that SSIF generalizes well to both unseen spatial resolutions and spectral resolutions. Moreover, SSIF can generate high-resolution images that improve the performance of downstream tasks (e.g., land use classification) by 1.7%-7%.
@article{mai2023ssif, title = {SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution}, author = {Mai, Gengchen and Lao, Ni and Sun, Weiwei and Ma, Yuchi and Song, Jiaming and Meng, Chenlin and Ma, Hongxu and Rao, Jinmeng and Li, Ziyuan and Ermon, Stefano}, year = {2023}, eprint = {2310.00413}, journal = {arXiv preprint arXiv:2310.00413}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, } -
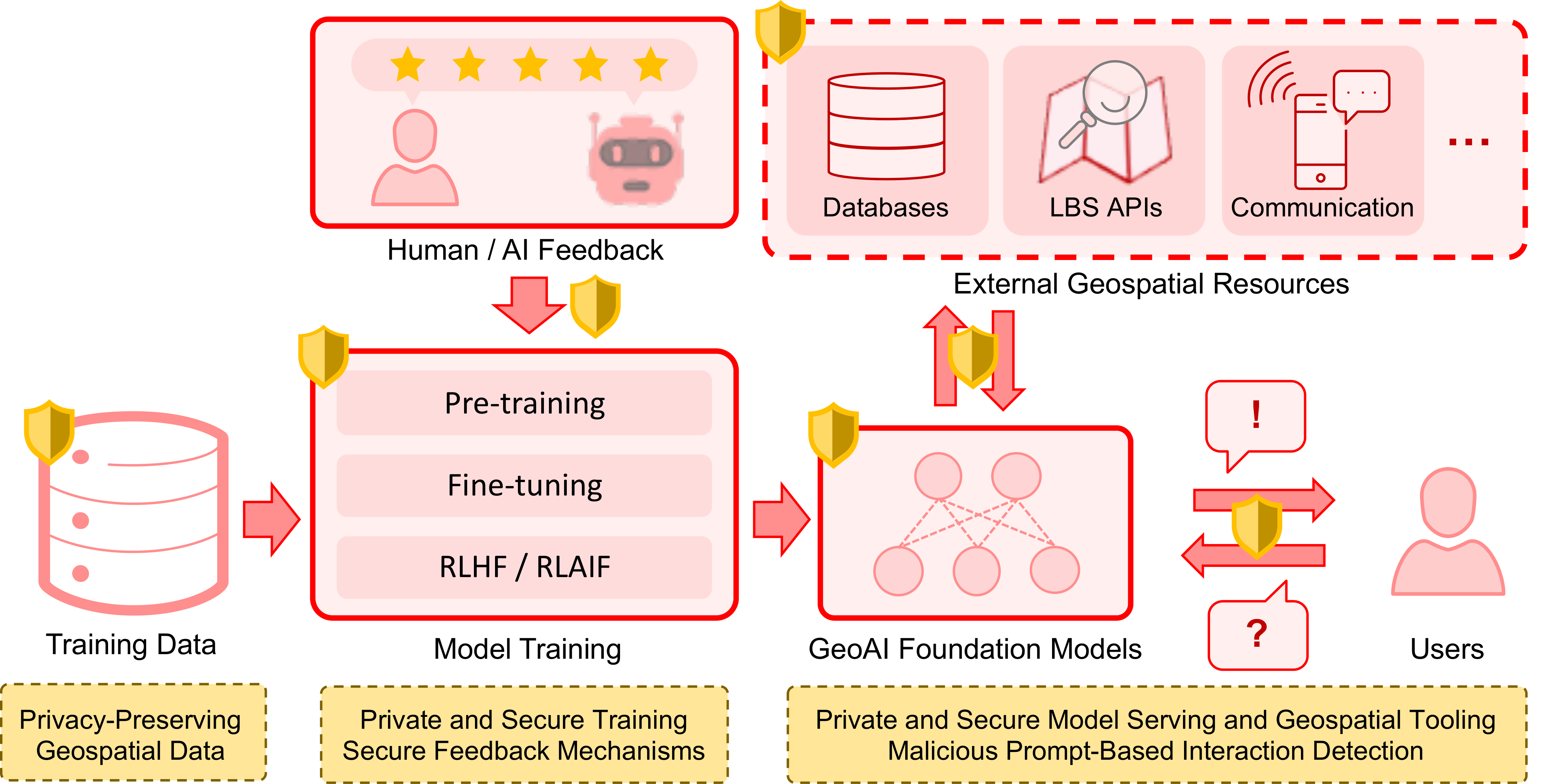 ACM SIGSPATIALBuilding Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation ModelsJinmeng Rao, Song Gao, Gengchen Mai, and Krzysztof JanowiczIn Proceedings of the 31st International Conference on Advances in Geographic Information Systems, 2023Highlight: Top Conference in Geographic Information Systems; Acceptance rate 37.2%
ACM SIGSPATIALBuilding Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation ModelsJinmeng Rao, Song Gao, Gengchen Mai, and Krzysztof JanowiczIn Proceedings of the 31st International Conference on Advances in Geographic Information Systems, 2023Highlight: Top Conference in Geographic Information Systems; Acceptance rate 37.2%In recent years we have seen substantial advances in foundation models for artificial intelligence, including language, vision, and multimodal models. Recent studies have highlighted the potential of using foundation models in geospatial artificial intelligence, known as GeoAI Foundation Models, for geographic question answering, remote sensing image understanding, map generation, and location-based services, among others. However, the development and application of GeoAI foundation models can pose serious privacy and security risks, which have not been fully discussed or addressed to date. This paper introduces the potential privacy and security risks throughout the lifecycle of GeoAI foundation models and proposes a comprehensive blueprint for research directions and preventative and control strategies. Through this vision paper, we hope to draw the attention of researchers and policymakers in geospatial domains to these privacy and security risks inherent in GeoAI foundation models and advocate for the development of privacy-preserving and secure GeoAI foundation models.
@inproceedings{rao2023psgeoai, title = {Building Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation Models}, author = {Rao, Jinmeng and Gao, Song and Mai, Gengchen and Janowicz, Krzysztof}, booktitle = {Proceedings of the 31st International Conference on Advances in Geographic Information Systems}, pages = {1--4}, year = {2023}, note = {Highlight: Top Conference in Geographic Information Systems; Acceptance rate 37.2\%}, } -
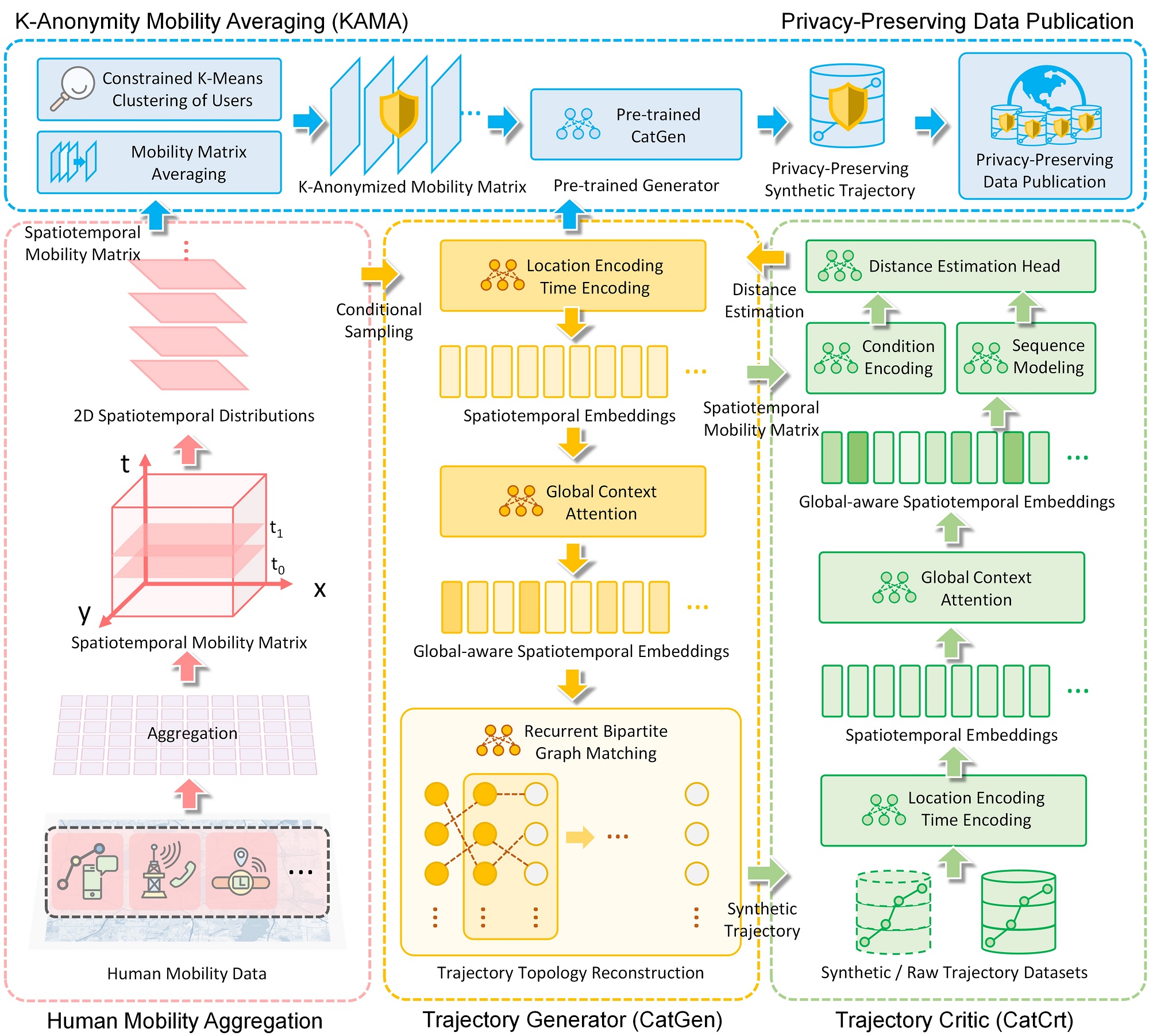 IJGISCATS: Conditional Adversarial Trajectory Synthesis for Privacy-Preserving Trajectory Data Publication Using Deep Learning ApproachesJinmeng Rao, Song Gao, and Sijia ZhuInternational Journal of Geographical Information Science, 2023Highlight: Top Journal in Geographic Information Science; SCI Q1 in CS, IS and Geography; Acceptance rate 12%
IJGISCATS: Conditional Adversarial Trajectory Synthesis for Privacy-Preserving Trajectory Data Publication Using Deep Learning ApproachesJinmeng Rao, Song Gao, and Sijia ZhuInternational Journal of Geographical Information Science, 2023Highlight: Top Journal in Geographic Information Science; SCI Q1 in CS, IS and Geography; Acceptance rate 12%The prevalence of ubiquitous location-aware devices and mobile Internet enables us to collect massive individual-level trajectory dataset from users. Such trajectory big data bring new opportunities to human mobility research but also raise public concerns with regard to location privacy. In this work, we present the Conditional Adversarial Trajectory Synthesis (CATS), a deep-learning-based GeoAI methodological framework for privacy-preserving trajectory data generation and publication. CATS applies K-anonymity to the underlying spatiotemporal distributions of human movements, which provides a distributional-level strong privacy guarantee. By leveraging conditional adversarial training on K-anonymized human mobility matrices, trajectory global context learning using the attention-based mechanism, and recurrent bipartite graph matching of adjacent trajectory points, CATS is able to reconstruct trajectory topology from conditionally sampled locations and generate high-quality individual-level synthetic trajectory data, which can serve as supplements or alternatives to raw data for privacy-preserving trajectory data publication. The experiment results on over 90k GPS trajectories show that our method has a better performance in privacy preservation, spatiotemporal characteristic preservation, and downstream utility compared with baseline methods, which brings new insights into privacy-preserving human mobility research using generative AI techniques and explores data ethics issues in GIScience.
@article{rao2023cats, title = {CATS: Conditional Adversarial Trajectory Synthesis for Privacy-Preserving Trajectory Data Publication Using Deep Learning Approaches}, author = {Rao, Jinmeng and Gao, Song and Zhu, Sijia}, journal = {International Journal of Geographical Information Science}, year = {2023}, volume = {37}, number = {12}, pages = {1-33}, note = {Highlight: Top Journal in Geographic Information Science; SCI Q1 in CS, IS and Geography; Acceptance rate 12\%}, } -
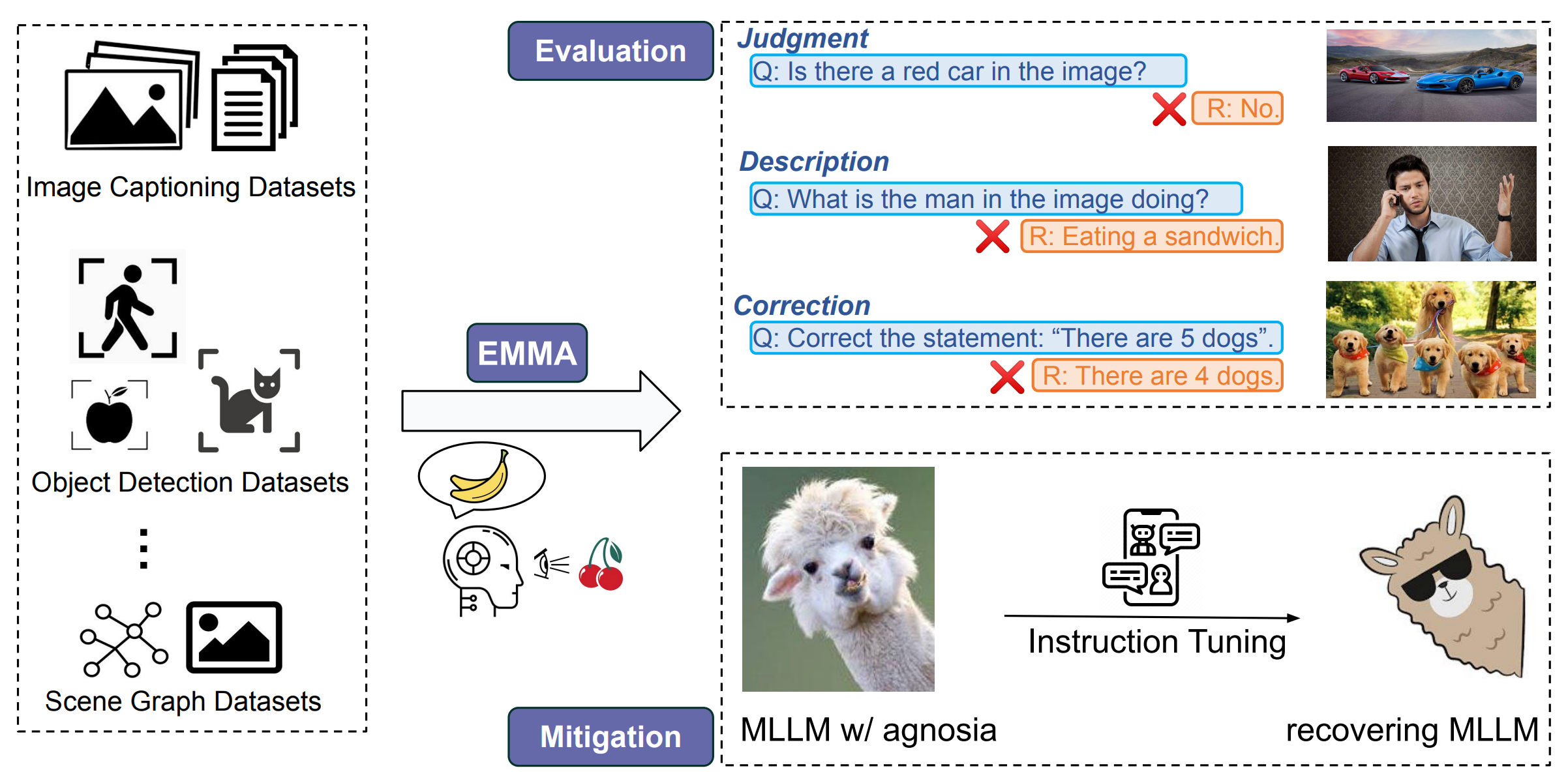 Google Research ConferenceEvaluation and Mitigation of Agnosia in Multimodal Large Language ModelsJinmeng Rao*, Jiaying Lu*, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Baochen Sun, Carl Yang, and Jie YangarXiv preprint arXiv:2309.04041, 2023Highlight: Trustworthy Multimodal Foundation Models; Multimodal Instruction Tuning; The poster version to be presented at Google Research Conference 2023
Google Research ConferenceEvaluation and Mitigation of Agnosia in Multimodal Large Language ModelsJinmeng Rao*, Jiaying Lu*, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Baochen Sun, Carl Yang, and Jie YangarXiv preprint arXiv:2309.04041, 2023Highlight: Trustworthy Multimodal Foundation Models; Multimodal Instruction Tuning; The poster version to be presented at Google Research Conference 2023While Multimodal Large Language Models (MLLMs) are widely used for a variety of vision-language tasks, one observation is that they sometimes misinterpret visual inputs or fail to follow textual instructions even in straightforward cases, leading to irrelevant responses, mistakes, and ungrounded claims. This observation is analogous to a phenomenon in neuropsychology known as Agnosia, an inability to correctly process sensory modalities and recognize things (e.g., objects, colors, relations). In our study, we adapt this similar concept to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process in neuropsychology, we propose a novel framework EMMA (Evaluation and Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module that automatically creates fine-grained and diverse visual question answering examples to assess the extent of agnosia in MLLMs comprehensively. We also develop a mitigation module to reduce agnosia in MLLMs through multimodal instruction tuning on fine-grained conversations. To verify the effectiveness of our framework, we evaluate and analyze agnosia in seven state-of-the-art MLLMs using 9K test samples. The results reveal that most of them exhibit agnosia across various aspects and degrees. We further develop a fine-grained instruction set and tune MLLMs to mitigate agnosia, which led to notable improvement in accuracy.
@article{lu2023evaluation, title = {Evaluation and Mitigation of Agnosia in Multimodal Large Language Models}, author = {Rao*, Jinmeng and Lu*, Jiaying and Chen, Kezhen and Guo, Xiaoyuan and Zhang, Yawen and Sun, Baochen and Yang, Carl and Yang, Jie}, journal = {arXiv preprint arXiv:2309.04041}, year = {2023}, note = {Highlight: Trustworthy Multimodal Foundation Models; Multimodal Instruction Tuning; The poster version to be presented at Google Research Conference 2023}, } -
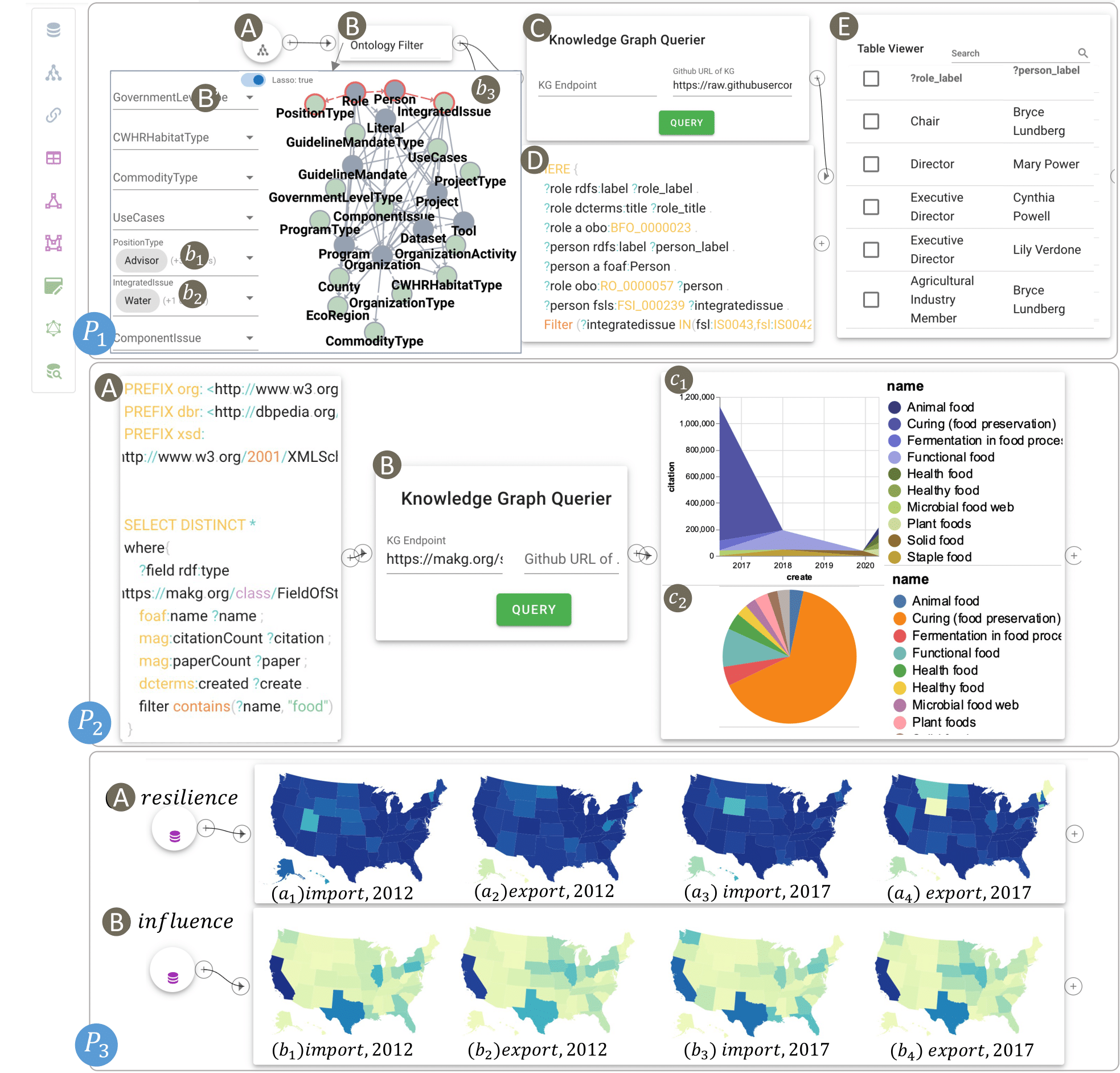 IEEE CG&AAn Interactive Knowledge and Learning Environment in Smart FoodshedsYamei Tu, Xiaoqi Wang, Rui Qiu, Han-Wei Shen, Michelle Miller, Jinmeng Rao, Song Gao, Patrick R Huber, Allan D Hollander, Matthew Lange, and othersIEEE Computer Graphics and Applications, 2023
IEEE CG&AAn Interactive Knowledge and Learning Environment in Smart FoodshedsYamei Tu, Xiaoqi Wang, Rui Qiu, Han-Wei Shen, Michelle Miller, Jinmeng Rao, Song Gao, Patrick R Huber, Allan D Hollander, Matthew Lange, and othersIEEE Computer Graphics and Applications, 2023The Internet of Food (IoF) is an emerging field in smart foodsheds, involving the creation of a knowledge graph (KG) about the environment, agriculture, food, diet, and health. However, the heterogeneity and size of the KG present challenges for downstream tasks, such as information retrieval and interactive exploration. To address those challenges, we propose an interactive knowledge and learning environment (IKLE) that integrates three programming and modeling languages to support multiple downstream tasks in the analysis pipeline. To make IKLE easier to use, we have developed algorithms to automate the generation of each language. In addition, we collaborated with domain experts to design and develop a dataflow visualization system, which embeds the automatic language generations into components and allows users to build their analysis pipeline by dragging and connecting components of interest. We have demonstrated the effectiveness of IKLE through three real-world case studies in smart foodsheds.
@article{tu2023interactive, title = {An Interactive Knowledge and Learning Environment in Smart Foodsheds}, author = {Tu, Yamei and Wang, Xiaoqi and Qiu, Rui and Shen, Han-Wei and Miller, Michelle and Rao, Jinmeng and Gao, Song and Huber, Patrick R and Hollander, Allan D and Lange, Matthew and others}, journal = {IEEE Computer Graphics and Applications}, year = {2023}, publisher = {IEEE}, } -
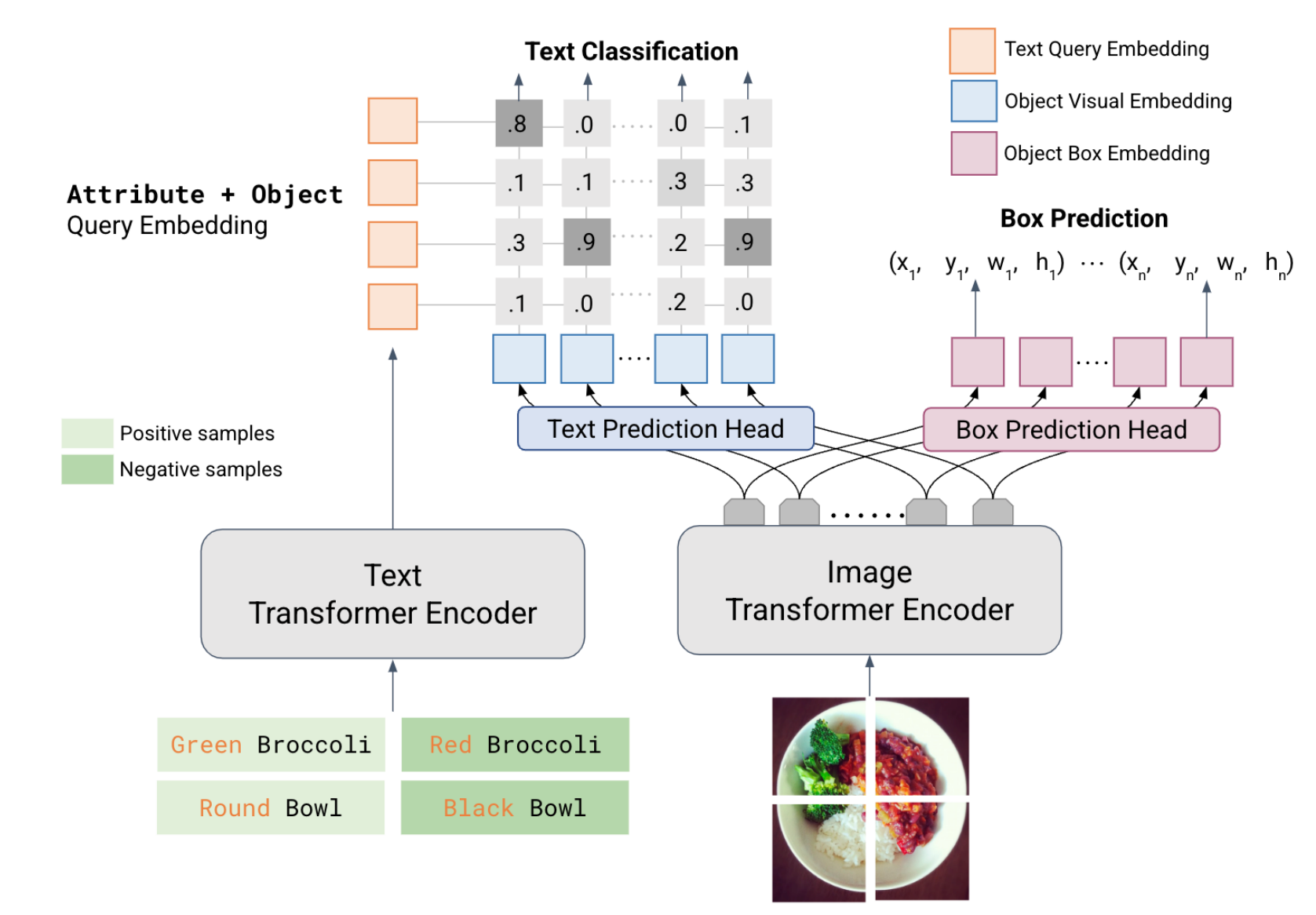 ARXIVLOWA: Localize Objects in the Wild with AttributesXiaoyuan Guo, Kezhen Chen, Jinmeng Rao, Yawen Zhang, Baochen Sun, and Jie YangarXiv preprint arXiv:2305.20047, 2023
ARXIVLOWA: Localize Objects in the Wild with AttributesXiaoyuan Guo, Kezhen Chen, Jinmeng Rao, Yawen Zhang, Baochen Sun, and Jie YangarXiv preprint arXiv:2305.20047, 2023We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
@article{guo2023lowa, title = {LOWA: Localize Objects in the Wild with Attributes}, author = {Guo, Xiaoyuan and Chen, Kezhen and Rao, Jinmeng and Zhang, Yawen and Sun, Baochen and Yang, Jie}, journal = {arXiv preprint arXiv:2305.20047}, year = {2023}, } -
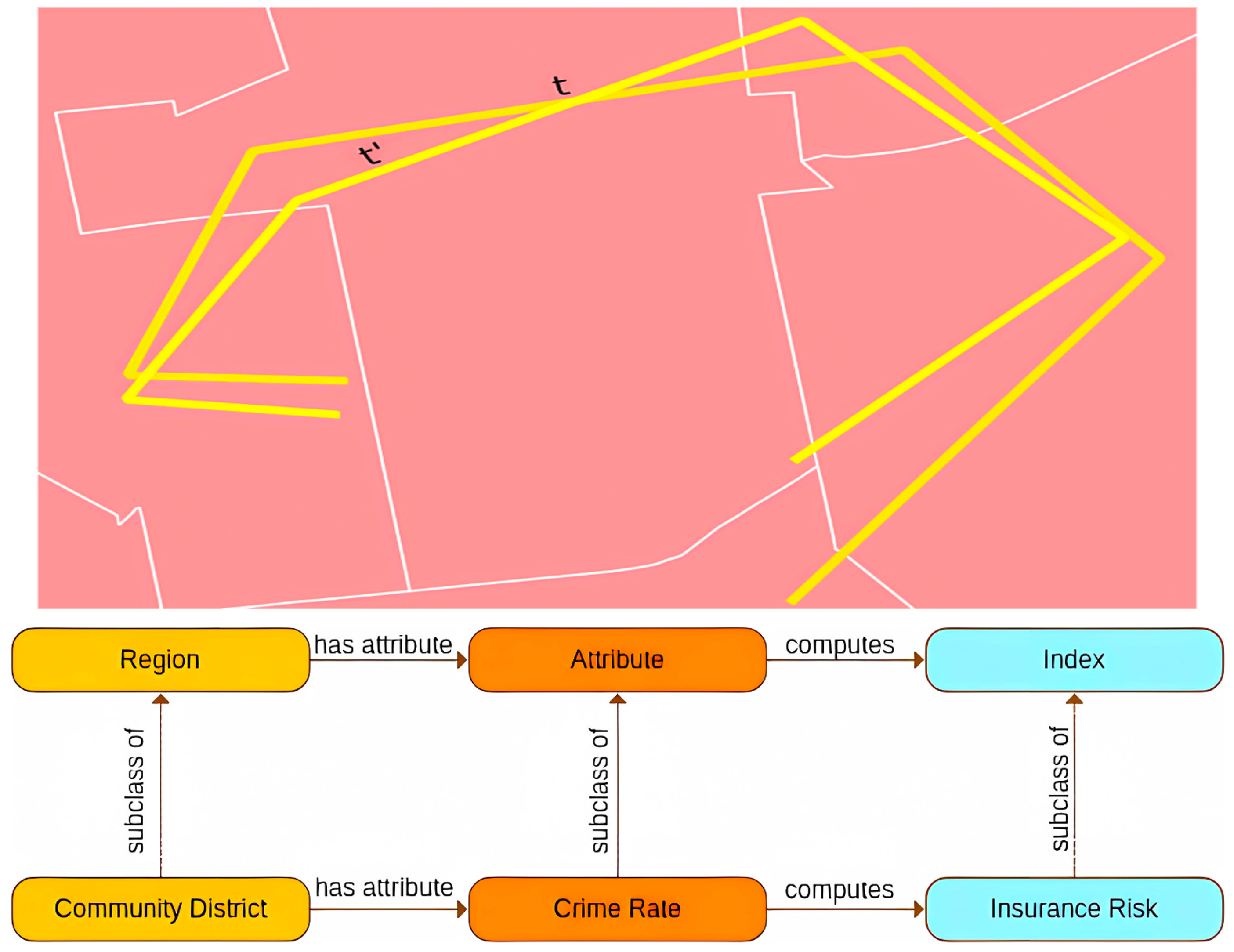 PLATIALHere is Not There: Measuring Entailment-based Trajectory Similarity for Location-Privacy Protection and BeyondZilong Liu, Krzysztof Janowicz, Kitty Currier, Meilin Shi, Jinmeng Rao, Song Gao, Ling Cai, and Anita GraserIn International Symposium on Platial Information Science, 2023
PLATIALHere is Not There: Measuring Entailment-based Trajectory Similarity for Location-Privacy Protection and BeyondZilong Liu, Krzysztof Janowicz, Kitty Currier, Meilin Shi, Jinmeng Rao, Song Gao, Ling Cai, and Anita GraserIn International Symposium on Platial Information Science, 2023While the paths humans take play out in social as well as physical space, measures to describe and compare their trajectories are carried out in abstract, typically Euclidean, space. When these measures are applied to trajectories of actual individuals in an application area, alterations that are inconsequential in abstract space may suddenly become problematic once overlaid with geographical reality. In this work, we present a different view on trajectory similarity by introducing a measure that utilizes logical entailment. This is an inferential perspective that considers facts as triple statements deduced from the social and environmental context, in which the travel takes place, and their practical implications. We suggest a formalization of entailment-based trajectory similarity, measured as the overlapping proportion of facts, which are spatial relation statements in our case study. With the proposed measure, we evaluate LSTM-TrajGAN, a privacy-preserving trajectory-generation model. The entailment-based model evaluation reveals potential consequences of disregarding the rich structure of geographical space (e.g., miscalculated insurance risk due to regional shifts in our toy example). Our work highlights the advantage of applying logical entailment to trajectory-similarity reasoning for location-privacy protection and beyond.
@inproceedings{liuhere, title = {Here is Not There: Measuring Entailment-based Trajectory Similarity for Location-Privacy Protection and Beyond}, author = {Liu, Zilong and Janowicz, Krzysztof and Currier, Kitty and Shi, Meilin and Rao, Jinmeng and Gao, Song and Cai, Ling and Graser, Anita}, booktitle = {International Symposium on Platial Information Science}, year = {2023}, } -
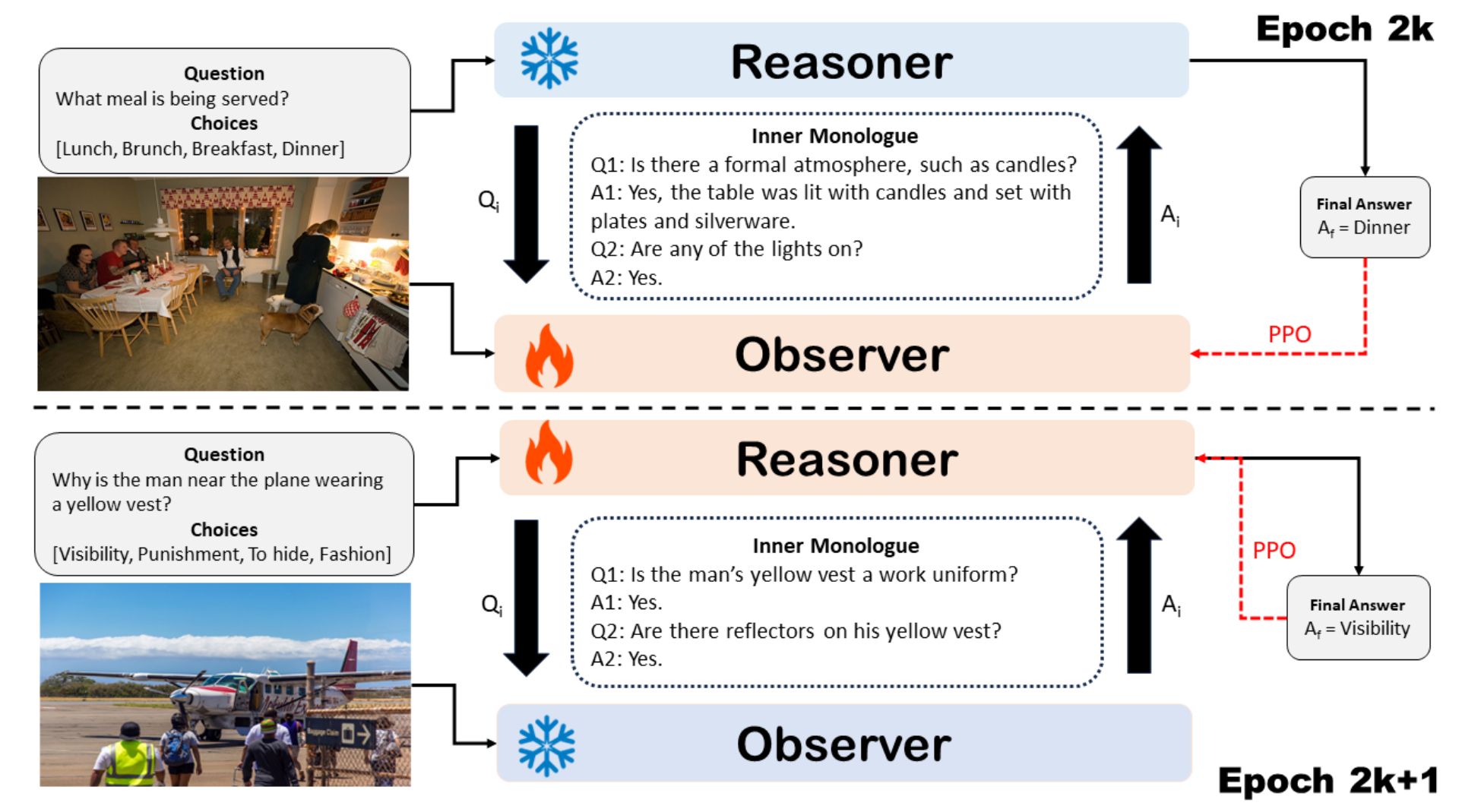 NeurIPS SoLaRTackling Vision Language Tasks Through Learning Inner MonologuesDiji Yang, Kezhen Chen, Jinmeng Rao, Xiaoyuan Guo, Yawen Zhang, Jie Yang, and Yi ZhangarXiv preprint arXiv:2308.09970, 2023Highlight: Multi-Agent Collaboration. To be presented at NeurIPS SoLaR workshop. The poster version was presented at BayLearn 2023
NeurIPS SoLaRTackling Vision Language Tasks Through Learning Inner MonologuesDiji Yang, Kezhen Chen, Jinmeng Rao, Xiaoyuan Guo, Yawen Zhang, Jie Yang, and Yi ZhangarXiv preprint arXiv:2308.09970, 2023Highlight: Multi-Agent Collaboration. To be presented at NeurIPS SoLaR workshop. The poster version was presented at BayLearn 2023Visual language tasks require AI models to comprehend and reason with both visual and textual content. Driven by the power of Large Language Models (LLMs), two prominent methods have emerged: (1) the hybrid integration between LLMs and Vision-Language Models (VLMs), where visual inputs are firstly converted into language descriptions by VLMs, serving as inputs for LLMs to generate final answer(s); (2) visual feature alignment in language space, where visual inputs are encoded as embeddings and projected to LLMs’ language space via further supervised fine-tuning. The first approach provides light training costs and interpretability but is hard to be optimized in an end-to-end fashion. The second approach presents decent performance, but feature alignment usually requires large amounts of training data and lacks interpretability. To tackle this dilemma, we propose a novel approach, Inner Monologue Multi-Modal Optimization (IMMO), to solve complex vision language problems by simulating inner monologue processes, a cognitive process in which an individual engages in silent verbal communication with themselves. We enable LLMs and VLMs to interact through natural language conversation and propose to use a two-stage training process to learn how to do the inner monologue (self-asking questions and answering questions). IMMO is evaluated on two popular tasks and the results suggest by emulating the cognitive phenomenon of internal dialogue, our approach can enhance reasoning and explanation abilities, contributing to the more effective fusion of vision and language models. More importantly, instead of using predefined human-crafted monologues, IMMO learns this process within the deep learning models, promising wider applicability to many different AI problems beyond vision language tasks.
@article{yang2023tackling, title = {Tackling Vision Language Tasks Through Learning Inner Monologues}, author = {Yang, Diji and Chen, Kezhen and Rao, Jinmeng and Guo, Xiaoyuan and Zhang, Yawen and Yang, Jie and Zhang, Yi}, journal = {arXiv preprint arXiv:2308.09970}, year = {2023}, note = {Highlight: Multi-Agent Collaboration. To be presented at NeurIPS SoLaR workshop. The poster version was presented at BayLearn 2023}, } -
 TGISChoosing GIS graduate programs from afar: Chinese students’ perspectivesYikang Wang, Yuhao Kang, Haokun Liu, Ce Hou, Bing Zhou, Shan Ye, Yuyan Liu, Jinmeng Rao, Zhenghao Pei, Xiang Ye, and othersTransactions in GIS, 2023
TGISChoosing GIS graduate programs from afar: Chinese students’ perspectivesYikang Wang, Yuhao Kang, Haokun Liu, Ce Hou, Bing Zhou, Shan Ye, Yuyan Liu, Jinmeng Rao, Zhenghao Pei, Xiang Ye, and othersTransactions in GIS, 2023With the increasing demands for geospatial analytics in industry and academia, the need for Geographic Information Systems/Science (GIS) education is on the rise. A growing number of departments in geography have launched or expanded their GIS graduate programs. However, the factors influencing students choosing GIS programs have not been examined yet. In this study, we looked at Chinese students applying for overseas GIS programs and examined factors influencing their decision-making. We distributed the survey in GISphere, one of the largest GIS international student communities, and 84 valid questionnaires were returned. We analyzed the spatial and demographic patterns of Chinese students applying for overseas GIS programs. We identify five main factors that affect their choices of GIS programs: (1) education quality and awareness, (2) physical, social, and political environments, (3) improved employment prospects, (4) personal recommendations, and (5) the application process. Our study offers implications for the development of GIS graduate programs. We anticipate that the conclusions drawn from this research will benefit and advance geography and GIS education globally.
@article{wang2023choosing, title = {Choosing GIS graduate programs from afar: Chinese students' perspectives}, author = {Wang, Yikang and Kang, Yuhao and Liu, Haokun and Hou, Ce and Zhou, Bing and Ye, Shan and Liu, Yuyan and Rao, Jinmeng and Pei, Zhenghao and Ye, Xiang and others}, journal = {Transactions in GIS}, volume = {27}, number = {2}, pages = {450--475}, year = {2023}, }









2022
-
 ACM SIGSPATIAL GEOKGMeasuring network resilience via geospatial knowledge graph: a case study of the us multi-commodity flow networkJinmeng Rao, Song Gao, Michelle Miller, and Alfonso MoralesIn Proceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Knowledge Graphs, 2022Highlight: Food System; Network Resilience; Geospatial Knowledge Graphs
ACM SIGSPATIAL GEOKGMeasuring network resilience via geospatial knowledge graph: a case study of the us multi-commodity flow networkJinmeng Rao, Song Gao, Michelle Miller, and Alfonso MoralesIn Proceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Knowledge Graphs, 2022Highlight: Food System; Network Resilience; Geospatial Knowledge GraphsQuantifying the resilience in the food system is important for food security issues. In this work, we present a geospatial knowledge graph (GeoKG)-based method for measuring the resilience of a multi-commodity flow network. Specifically, we develop a CFS-GeoKG ontology to describe geospatial semantics of a multi-commodity flow network comprehensively, and design resilience metrics that measure the node-level and network-level dependence of single-sourcing, distant, or non-adjacent suppliers/customers in food supply chains. We conduct a case study of the US state-level agricultural multi-commodity flow network with hierarchical commodity types. The results indicate that, by leveraging GeoKG, our method supports measuring both node-level and network-level resilience across space and over time and also helps discover concentration patterns of agricultural resources in the spatial network at different geographic scales.
@inproceedings{rao2022measuring, title = {Measuring network resilience via geospatial knowledge graph: a case study of the us multi-commodity flow network}, author = {Rao, Jinmeng and Gao, Song and Miller, Michelle and Morales, Alfonso}, booktitle = {Proceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Knowledge Graphs}, pages = {17--25}, year = {2022}, note = {Highlight: Food System; Network Resilience; Geospatial Knowledge Graphs}, } -
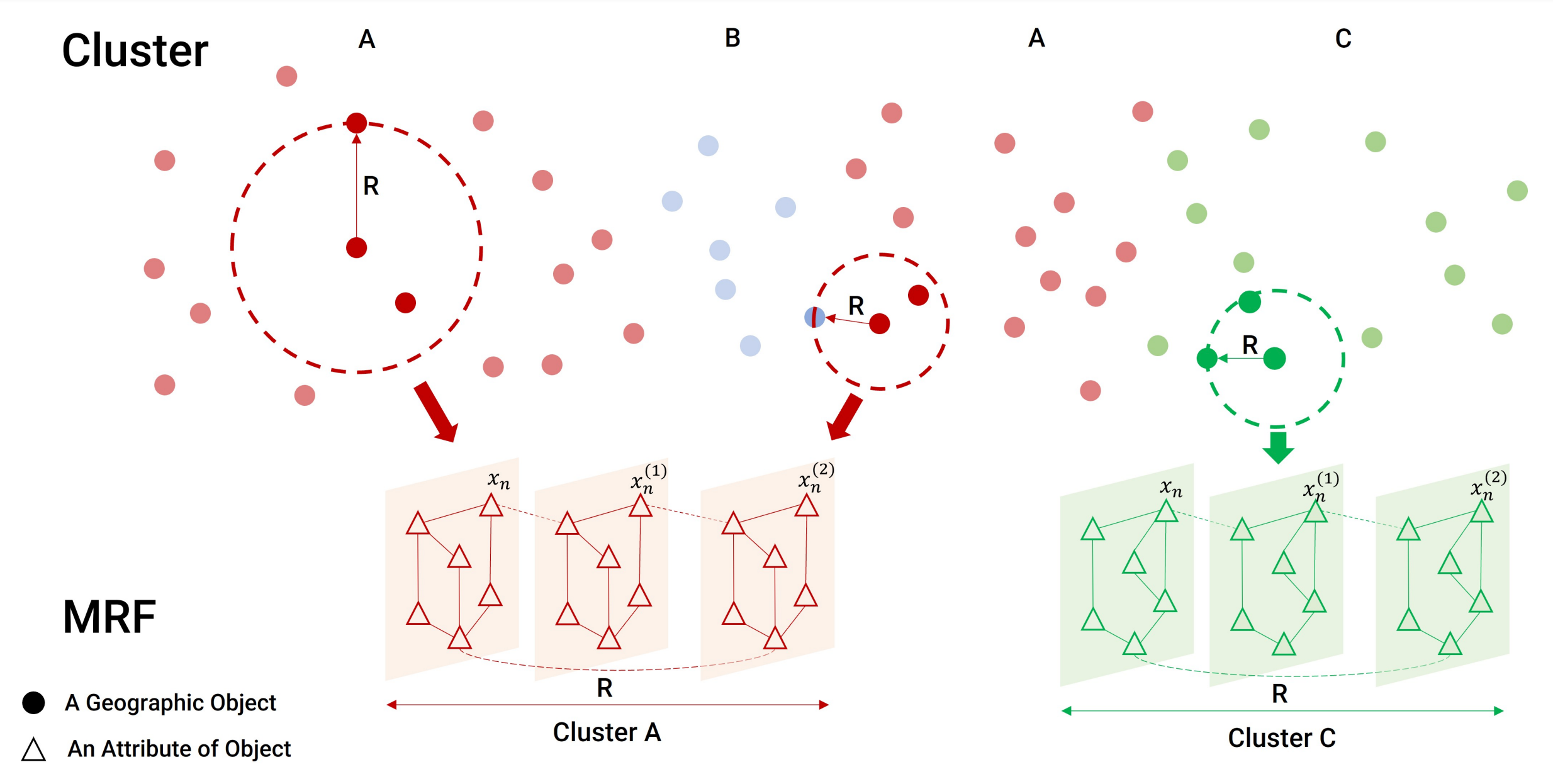 IJGISSTICC: a multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguityYuhao Kang, Kunlin Wu, Song Gao, Ignavier Ng, Jinmeng Rao, Shan Ye, Fan Zhang, and Teng FeiInternational Journal of Geographical Information Science, 2022
IJGISSTICC: a multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguityYuhao Kang, Kunlin Wu, Song Gao, Ignavier Ng, Jinmeng Rao, Shan Ye, Fan Zhang, and Teng FeiInternational Journal of Geographical Information Science, 2022Spatial clustering has been widely used for spatial data mining and knowledge discovery. An ideal multivariate spatial clustering should consider both spatial contiguity and aspatial attributes. Existing spatial clustering approaches may face challenges for discovering repeated geographic patterns with spatial contiguity maintained. In this paper, we propose a Spatial Toeplitz Inverse Covariance-Based Clustering (STICC) method that considers both attributes and spatial relationships of geographic objects for multivariate spatial clustering. A subregion is created for each geographic object serving as the basic unit when performing clustering. A Markov random field is then constructed to characterize the attribute dependencies of subregions. Using a spatial consistency strategy, nearby objects are encouraged to belong to the same cluster. To test the performance of the proposed STICC algorithm, we apply it in two use cases. The comparison results with several baseline methods show that the STICC outperforms others significantly in terms of adjusted rand index and macro-F1 score. Join count statistics is also calculated and shows that the spatial contiguity is well preserved by STICC. Such a spatial clustering method may benefit various applications in the fields of geography, remote sensing, transportation, and urban planning, etc.
@article{kang2022sticc, title = {STICC: a multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguity}, author = {Kang, Yuhao and Wu, Kunlin and Gao, Song and Ng, Ignavier and Rao, Jinmeng and Ye, Shan and Zhang, Fan and Fei, Teng}, journal = {International Journal of Geographical Information Science}, volume = {36}, number = {8}, pages = {1518--1549}, year = {2022}, publisher = {Taylor \& Francis}, }


2021
-
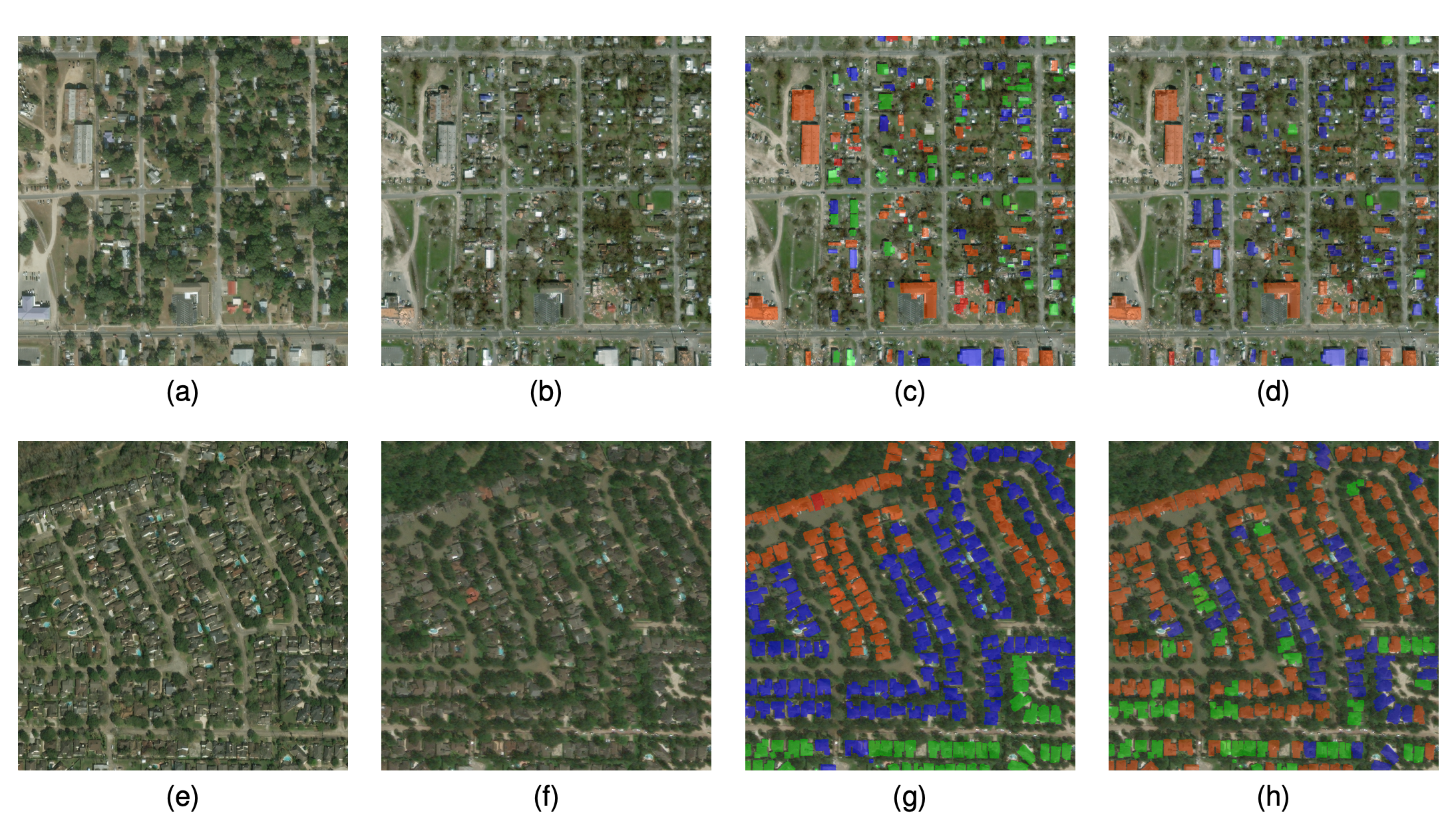 IEEE IGARSSSpatiotemporal contrastive representation learning for building damage classificationBo Peng, Qunying Huang, and Jinmeng RaoIn 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, 2021Highlight: Spatiotemporal Contrastive Representation Learning; Acceptance rate 34.2%
IEEE IGARSSSpatiotemporal contrastive representation learning for building damage classificationBo Peng, Qunying Huang, and Jinmeng RaoIn 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, 2021Highlight: Spatiotemporal Contrastive Representation Learning; Acceptance rate 34.2%Automatic building damage assessment after natural disasters is important for emergency response. While existing supervised deep learning models achieved good performance on building damage classification, these models require massive human labels for training. Additionally, pre-trained models often fail to generalize well to new disaster events due to gaps between domains associated with training and testing data. In response, this study proposes a novel spatiotemporal contrastive representation learning model for learning features of building damages with big unlabeled data. Experimental results demonstrate superior performance of such features on classifying building damages resulting from various natural disasters (e.g., hurricanes, floods, wildfires, earthquakes, etc.) across different geographic locations worldwide, compared with the state-of-the-art supervised methods.
@inproceedings{peng2021spatiotemporal, title = {Spatiotemporal contrastive representation learning for building damage classification}, author = {Peng, Bo and Huang, Qunying and Rao, Jinmeng}, booktitle = {2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS}, pages = {8562--8565}, year = {2021}, organization = {IEEE}, note = {Highlight: Spatiotemporal Contrastive Representation Learning; Acceptance rate 34.2\%}, } -
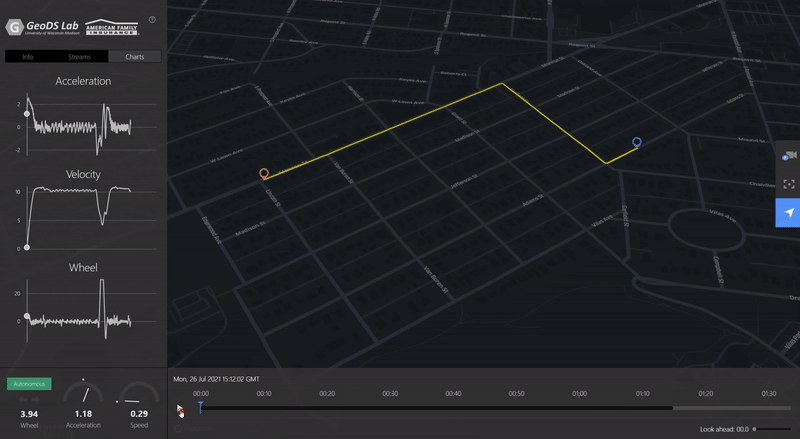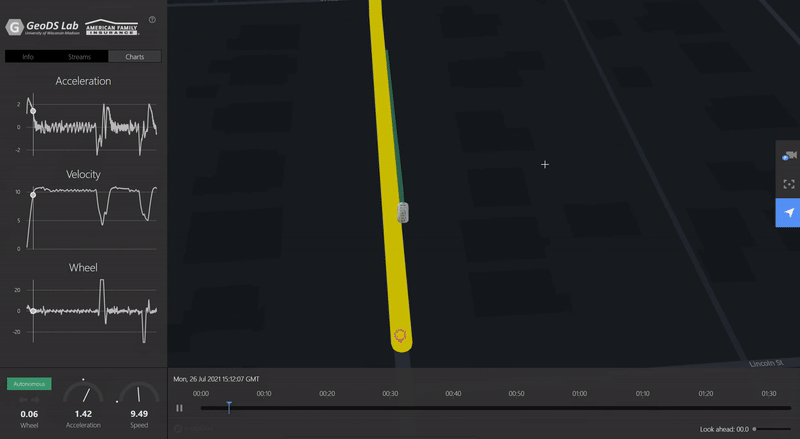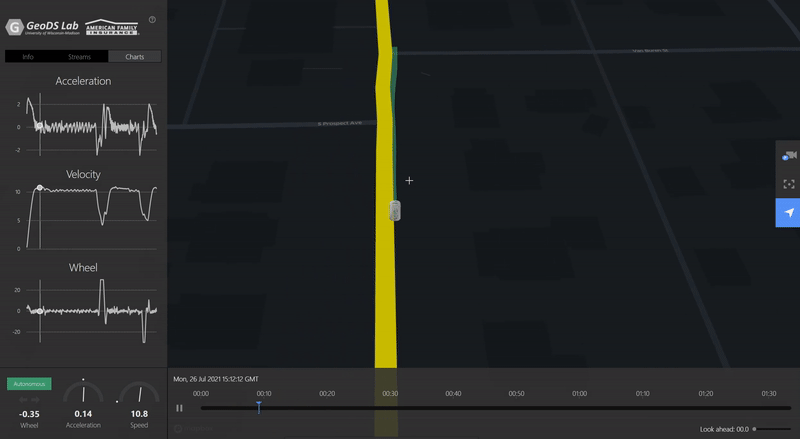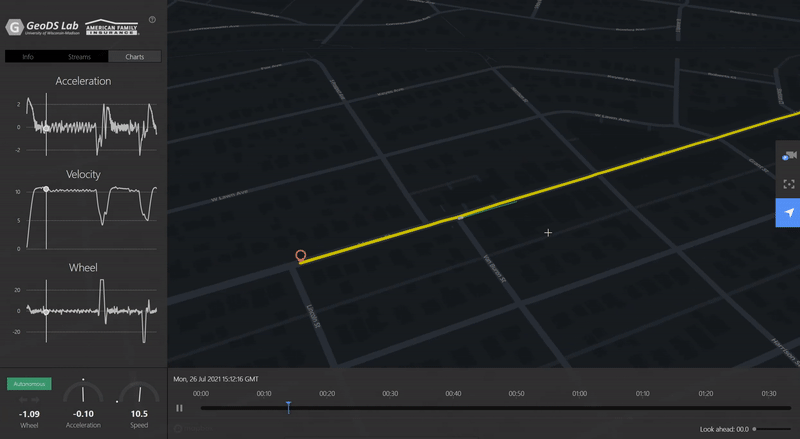 ACM SIGSPATIAL GEOAIVTSV: A privacy-preserving vehicle trajectory simulation and visualization platform using deep reinforcement learningJinmeng Rao, Song Gao, and Xiaojin ZhuIn Proceedings of the 4th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, 2021Highlight: Deep Reinforcement Learning; Personalized Driving Simulation [ Video Demo ]
ACM SIGSPATIAL GEOAIVTSV: A privacy-preserving vehicle trajectory simulation and visualization platform using deep reinforcement learningJinmeng Rao, Song Gao, and Xiaojin ZhuIn Proceedings of the 4th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, 2021Highlight: Deep Reinforcement Learning; Personalized Driving Simulation [ Video Demo ]Trajectory data is among the most sensitive data and the society increasingly raises privacy concerns. In this demo paper, we present a privacy-preserving Vehicle Trajectory Simulation and Visualization (VTSV) web platform (demo video: https://youtu.be/NY5L4bu2kTU), which automatically generates navigation routes between given pairs of origins and destinations and employs a deep reinforcement learning model to simulate vehicle trajectories with customized driving behaviors such as normal driving, overspeed, aggressive acceleration, and aggressive turning. The simulated vehicle trajectory data contain high-sample-rate of attributes including GPS location, speed, acceleration, and steering angle, and such data are visualized in VTSV using streetscape.gl, an autonomous driving data visualization framework. Location privacy protection methods such as origin-destination geomasking and trajectory k-anonymity are integrated into the platform to support privacy-preserving trajectory data generation and publication. We design two application scenarios to demonstrate how VTSV performs location privacy protection and customize driving behavior, respectively. The demonstration shows that VTSV is able to mitigate data privacy, sparsity, and imbalance sampling issues, which offers new insights into driving trajectory simulation and GeoAI-powered privacy-preserving data publication.
@inproceedings{rao2021vtsv, title = {VTSV: A privacy-preserving vehicle trajectory simulation and visualization platform using deep reinforcement learning}, author = {Rao, Jinmeng and Gao, Song and Zhu, Xiaojin}, booktitle = {Proceedings of the 4th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery}, pages = {43--46}, year = {2021}, note = {Highlight: Deep Reinforcement Learning; Personalized Driving Simulation <a href="https://www.youtube.com/watch?v=NY5L4bu2kTU">[ Video Demo ]</a>}, } -
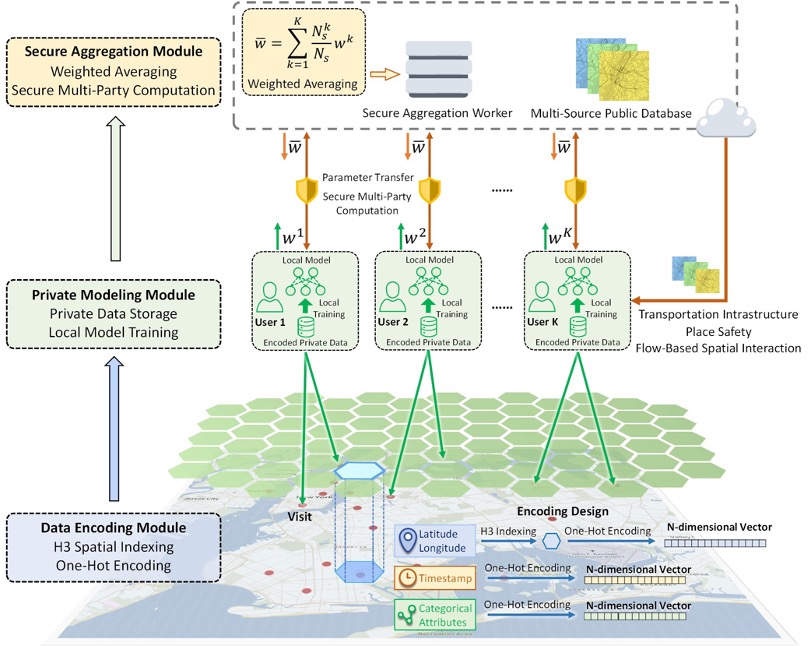 TGISA privacy-preserving framework for location recommendation using decentralized collaborative machine learningJinmeng Rao, Song Gao, Mingxiao Li, and Qunying HuangTransactions in GIS, 2021Highlight: Flagship Journal in Geographic Information Systems; Recognized as the first work on Federated Learning + Spatial Data Sciences (Graser, A. et al 2022)
TGISA privacy-preserving framework for location recommendation using decentralized collaborative machine learningJinmeng Rao, Song Gao, Mingxiao Li, and Qunying HuangTransactions in GIS, 2021Highlight: Flagship Journal in Geographic Information Systems; Recognized as the first work on Federated Learning + Spatial Data Sciences (Graser, A. et al 2022)The nowadays ubiquitous location-aware mobile devices have contributed to the rapid growth of individual-level location data. Such data are usually collected by location-based service platforms as training data to improve their predictive models’ performance, but the collection of such data may raise public concerns about privacy issues. In this study, we introduce a privacy-preserving location recommendation framework based on a decentralized collaborative machine learning approach: federated learning. Compared with traditional centralized learning frameworks, we keep users’ data on their own devices and train the model locally so that their data remain private. The local model parameters are aggregated and updated through secure multiple-party computation to achieve collaborative learning among users while preserving privacy. Our framework also integrates information about transportation infrastructure, place safety, and flow-based spatial interaction to further improve recommendation accuracy. We further design two attack cases to examine the privacy protection effectiveness and robustness of the framework. The results show that our framework achieves a better balance on the privacy–utility trade-off compared with traditional centralized learning methods. The results and ensuing discussion offer new insights into privacy-preserving geospatial artificial intelligence and promote geoprivacy in location-based services.
@article{rao2021privacy, title = {A privacy-preserving framework for location recommendation using decentralized collaborative machine learning}, author = {Rao, Jinmeng and Gao, Song and Li, Mingxiao and Huang, Qunying}, journal = {Transactions in GIS}, year = {2021}, note = {Highlight: Flagship Journal in Geographic Information Systems; Recognized as the first work on Federated Learning + Spatial Data Sciences <a href="https://publications.ait.ac.at/en/publications/on-the-role-of-spatial-data-science-for-federated-learning">(Graser, A. et al 2022)</a>}, } -
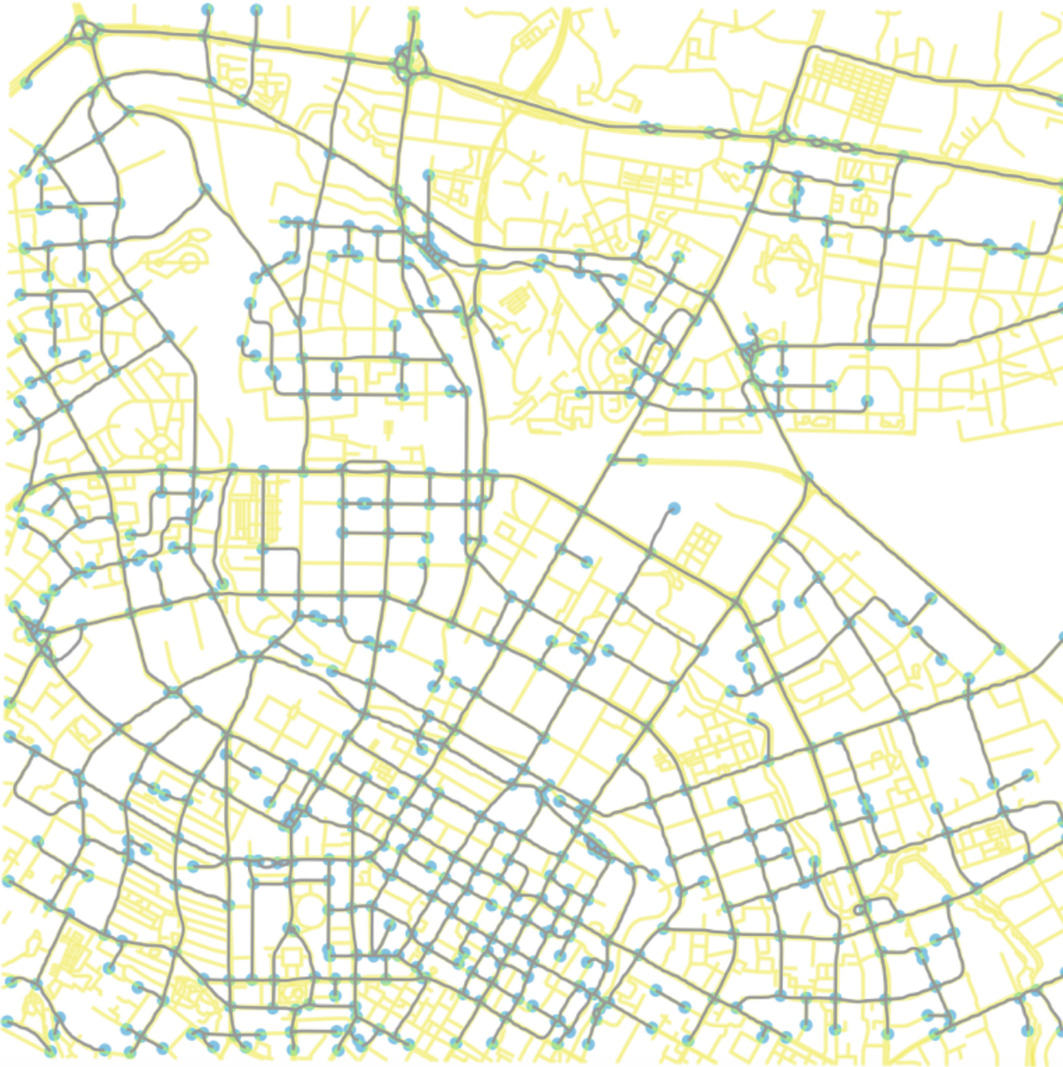 BOOK CHAPTERAutomatic urban road network extraction from massive GPS trajectories of taxisSong Gao, Mingxiao Li, Jinmeng Rao, Gengchen Mai, Timothy Prestby, Joseph Marks, and Yingjie HuIn Handbook of Big Geospatial Data, 2021
BOOK CHAPTERAutomatic urban road network extraction from massive GPS trajectories of taxisSong Gao, Mingxiao Li, Jinmeng Rao, Gengchen Mai, Timothy Prestby, Joseph Marks, and Yingjie HuIn Handbook of Big Geospatial Data, 2021Urban road networks are fundamental transportation infrastructures in daily life and essential in digital maps to support vehicle routing and navigation. Traditional methods of map vector data generation based on surveyor’s field work and map digitalization are costly and have a long update period. In the Big Data age, large-scale GPS-enabled taxi trajectories and high-volume ride-sharing datasets are increasingly available. These datasets provide high-resolution spatiotemporal information about urban traffic along road networks. In this study, we present a novel geospatial-big-data-driven framework that includes trajectory compression, clustering, and vectorization to automatically generate urban road geometric information. A case study is conducted using a large-scale DiDi ride-sharing GPS dataset in the city of Chengdu in China. We compare the results of our automatic extraction method with the road layer downloaded from OpenStreetMap. We measure the quality and demonstrate the effectiveness of our road extraction method regarding accuracy, spatial coverage and connectivity. The proposed framework shows a good potential to update fundamental road transportation information for smart-city development and intelligent transportation management using geospatial big data.
@incollection{gao2021automatic, title = {Automatic urban road network extraction from massive GPS trajectories of taxis}, author = {Gao, Song and Li, Mingxiao and Rao, Jinmeng and Mai, Gengchen and Prestby, Timothy and Marks, Joseph and Hu, Yingjie}, booktitle = {Handbook of Big Geospatial Data}, pages = {261--283}, year = {2021}, publisher = {Springer International Publishing Cham}, } -
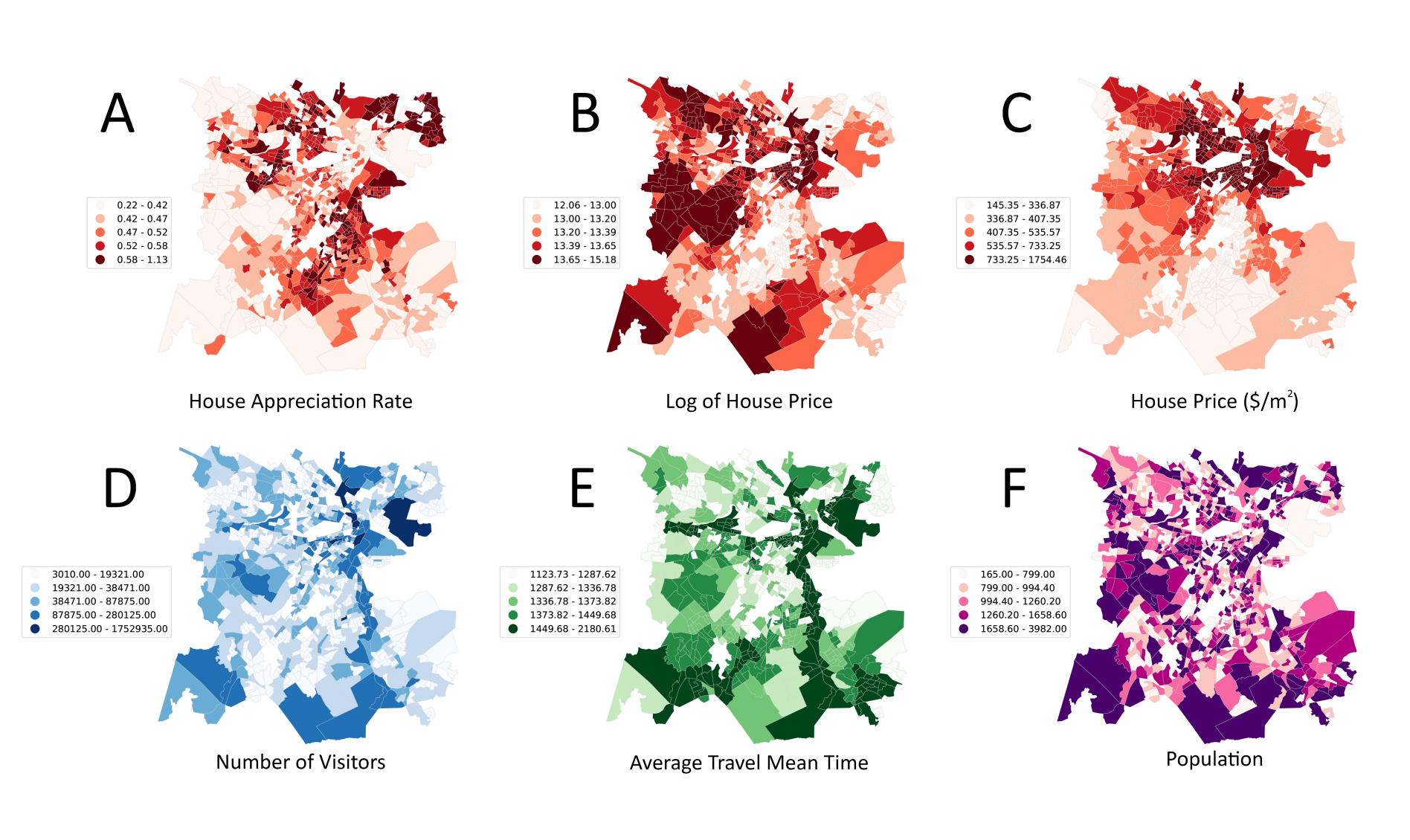 LUPUnderstanding house price appreciation using multi-source big geo-data and machine learningYuhao Kang, Fan Zhang, Wenzhe Peng, Song Gao, Jinmeng Rao, Fabio Duarte, and Carlo RattiLand Use Policy, 2021
LUPUnderstanding house price appreciation using multi-source big geo-data and machine learningYuhao Kang, Fan Zhang, Wenzhe Peng, Song Gao, Jinmeng Rao, Fabio Duarte, and Carlo RattiLand Use Policy, 2021Understanding house price appreciation benefits place-based decision makings and real estate market analyses. Although large amounts of interests have been paid in the house price modeling, limited work has focused on evaluating the price appreciation rate. In this study, we propose a data-fusion framework to examine how well house price appreciation potentials can be predicted by combining multiple data sources. We used data sets including house structural attributes, house photos, locational amenities, street view images, transportation accessibility, visitor patterns, and socioeconomic attributes of neighborhoods to enrich our understanding of the real estate appreciation and its predictive modeling. As a case study, we investigate more than 20,000 houses in the Greater Boston Area, and discuss the spatial dependency of house price appreciations, influential variables and their relationships. In detail, we extract deep features from street view images and house photos using a deep learning model, merging features from multi-source data and modeling house price appreciation using machine learning models and the geographically weighted regression at two spatial scales: fine-scale point level and aggregated neighborhood level. Results show that the house price appreciation rate can be modeled with high accuracy using the proposed framework (R2 = 0.74 for gradient boosting machine at neighborhood-scale). We discovered that houses with low house prices and small house areas may have a higher house appreciation potential. Our results provide insights into how multi-source big geo-data can be employed in machine learning frameworks to characterize real estate price trends and help understand human settlements for policy-making.
@article{kang2021understanding, title = {Understanding house price appreciation using multi-source big geo-data and machine learning}, author = {Kang, Yuhao and Zhang, Fan and Peng, Wenzhe and Gao, Song and Rao, Jinmeng and Duarte, Fabio and Ratti, Carlo}, journal = {Land Use Policy}, volume = {111}, pages = {104919}, year = {2021}, publisher = {Pergamon}, } -
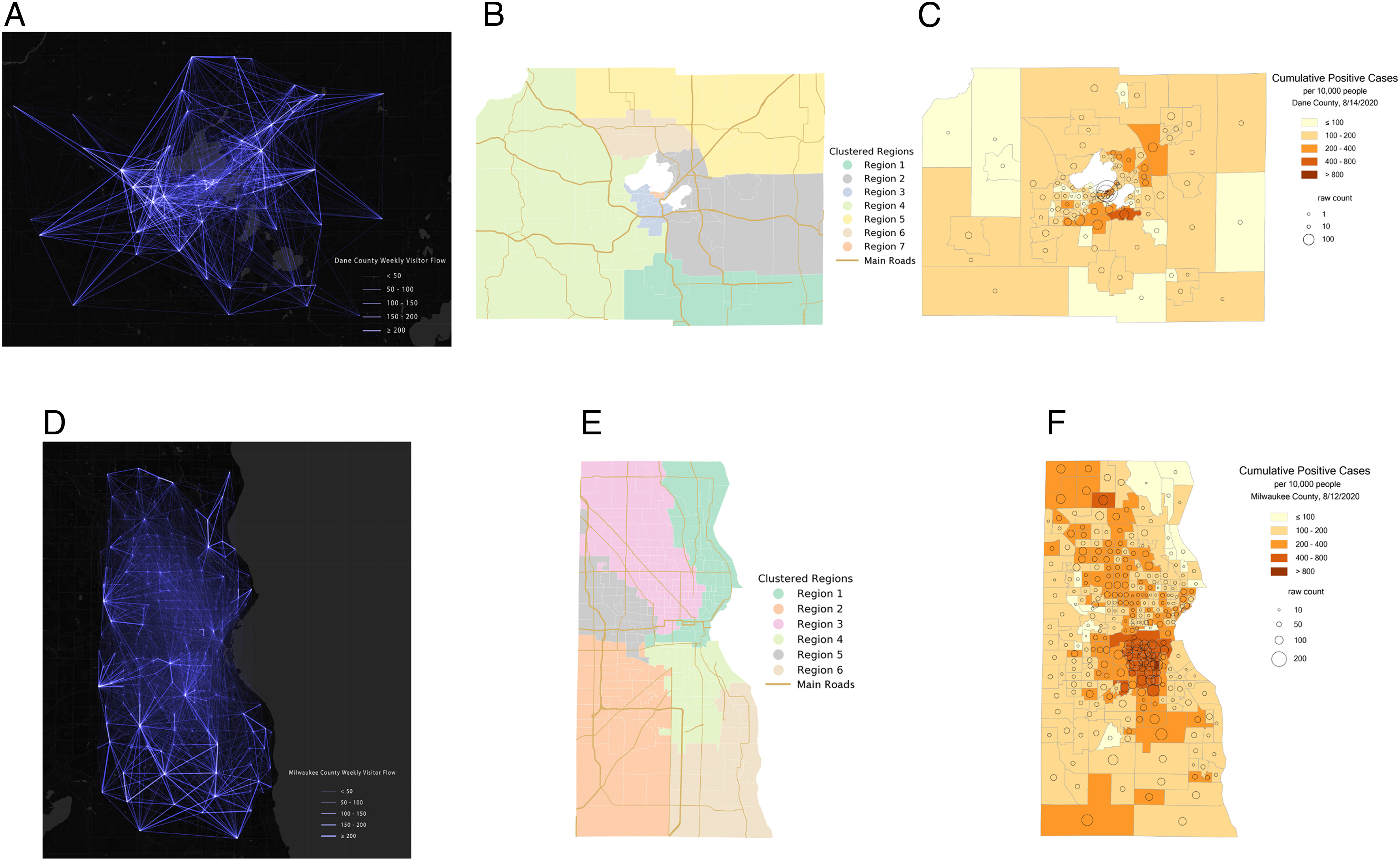 PNASIntracounty modeling of COVID-19 infection with human mobility: Assessing spatial heterogeneity with business traffic, age, and raceXiao Hou, Song Gao, Qin Li, Yuhao Kang, Nan Chen, Kaiping Chen, Jinmeng Rao, Jordan S Ellenberg, and Jonathan A PatzProceedings of the National Academy of Sciences, 2021
PNASIntracounty modeling of COVID-19 infection with human mobility: Assessing spatial heterogeneity with business traffic, age, and raceXiao Hou, Song Gao, Qin Li, Yuhao Kang, Nan Chen, Kaiping Chen, Jinmeng Rao, Jordan S Ellenberg, and Jonathan A PatzProceedings of the National Academy of Sciences, 2021The COVID-19 pandemic is a global threat presenting health, economic, and social challenges that continue to escalate. Metapopulation epidemic modeling studies in the susceptible–exposed–infectious–removed (SEIR) style have played important roles in informing public health policy making to mitigate the spread of COVID-19. These models typically rely on a key assumption on the homogeneity of the population. This assumption certainly cannot be expected to hold true in real situations; various geographic, socioeconomic, and cultural environments affect the behaviors that drive the spread of COVID-19 in different communities. What’s more, variation of intracounty environments creates spatial heterogeneity of transmission in different regions. To address this issue, we develop a human mobility flow-augmented stochastic SEIR-style epidemic modeling framework with the ability to distinguish different regions and their corresponding behaviors. This modeling framework is then combined with data assimilation and machine learning techniques to reconstruct the historical growth trajectories of COVID-19 confirmed cases in two counties in Wisconsin. The associations between the spread of COVID-19 and business foot traffic, race and ethnicity, and age structure are then investigated. The results reveal that, in a college town (Dane County), the most important heterogeneity is age structure, while, in a large city area (Milwaukee County), racial and ethnic heterogeneity becomes more apparent. Scenario studies further indicate a strong response of the spread rate to various reopening policies, which suggests that policy makers may need to take these heterogeneities into account very carefully when designing policies for mitigating the ongoing spread of COVID-19 and reopening.
@article{hou2021intracounty, title = {Intracounty modeling of COVID-19 infection with human mobility: Assessing spatial heterogeneity with business traffic, age, and race}, author = {Hou, Xiao and Gao, Song and Li, Qin and Kang, Yuhao and Chen, Nan and Chen, Kaiping and Rao, Jinmeng and Ellenberg, Jordan S and Patz, Jonathan A}, journal = {Proceedings of the National Academy of Sciences}, volume = {118}, number = {24}, pages = {e2020524118}, year = {2021}, publisher = {National Academy of Sciences}, } -
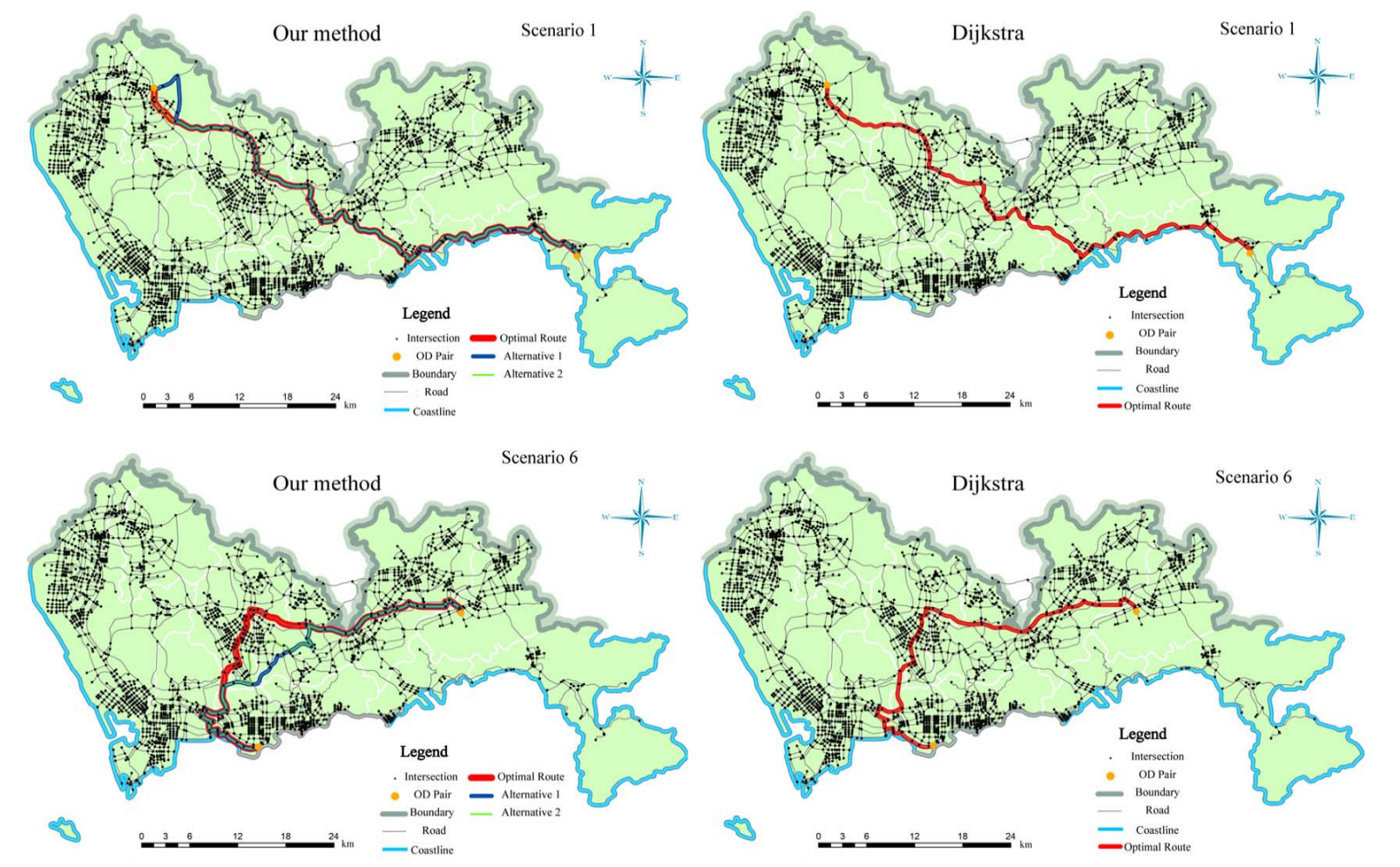 IEEE T-ITSUrban multiple route planning model using dynamic programming in reinforcement learningNingyezi Peng, Yuliang Xi, Jinmeng Rao, Xiangyuan Ma, and Fu RenIEEE Transactions on Intelligent Transportation Systems, 2021
IEEE T-ITSUrban multiple route planning model using dynamic programming in reinforcement learningNingyezi Peng, Yuliang Xi, Jinmeng Rao, Xiangyuan Ma, and Fu RenIEEE Transactions on Intelligent Transportation Systems, 2021With the development of the economy and the acceleration of urbanization, traffic congestion has become a worldwide problem. Advances in mobile Internet and sensor technologies have increased real-time data sharing, providing a new opportunity for urban route planning. However, due to the difficulty of handling complex global information, making correct decisions in large-scale and complex traffic environments is a problem that urgently needs to be solved. In this paper, a multiple route planning model (multi-route dynamic programming (DP) model) is proposed to solve the urban route planning problem with traffic flow information. In particular, we adopt the DP algorithm in this model, design a reward function suitable for urban path planning problems, and generate multiple routes based on the Q values. In addition, we design different scenarios using real-world road networks to test our model. Through the experiments, we demonstrate that our model has the potential to yield optimal results under large-scale scenarios with high efficiency. The advantages of integrating the distance contribution index (DCI) in the reward function are also elaborated. Moreover, our model can provide alternative routes to divert traffic from the optimal route, thus mitigating the congestion drift problem.
@article{peng2021urban, title = {Urban multiple route planning model using dynamic programming in reinforcement learning}, author = {Peng, Ningyezi and Xi, Yuliang and Rao, Jinmeng and Ma, Xiangyuan and Ren, Fu}, journal = {IEEE Transactions on Intelligent Transportation Systems}, volume = {23}, number = {7}, pages = {8037--8047}, year = {2021}, publisher = {IEEE}, } -
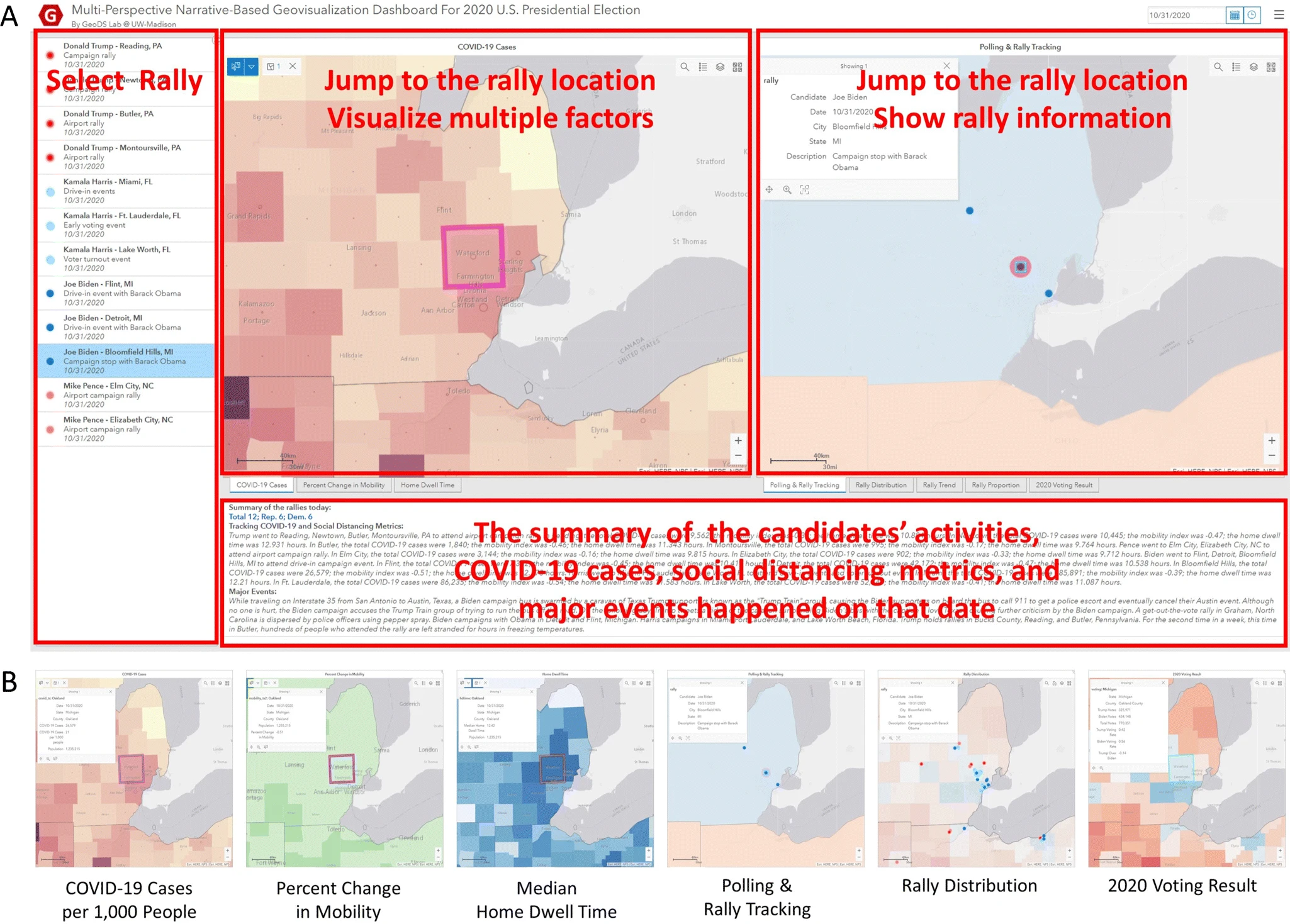 JGSAA multi-perspective narrative-based geovisualization dashboard for the 2020 US presidential electionJinmeng Rao, Kexin Chen, Ellie Fan Yang, Jacob Kruse, Kyler Hudson, and Song GaoJournal of Geovisualization and Spatial Analysis, 2021
JGSAA multi-perspective narrative-based geovisualization dashboard for the 2020 US presidential electionJinmeng Rao, Kexin Chen, Ellie Fan Yang, Jacob Kruse, Kyler Hudson, and Song GaoJournal of Geovisualization and Spatial Analysis, 2021In this paper, we design and implement a map dashboard that combines spatio-temporal visualization and interactive narrative to comprehensively illustrate the 2020 US presidential election. Specifically, our dashboard takes campaign rallies and major events as narrative clues and integrates multi-perspective factors (e.g., the spatial spread of COVID-19, social distancing adherence, poll results) for visualization and statistical analysis. Compared with traditional methods and products, our integrated multi-perspective solution better balances the narrative property and the geovisualization property of a dashboard, making it suitable for illustrating social or political events that happened on a large geographic scale. The result shows that our narrative-based geovisualization dashboard may be used for demonstrating and associating multiple factors with partisanship and has the potential to help users explore the interaction between policies controlling COVID-19, social distancing, and partisanship across the country during the 2020 US presidential election.
@article{rao2021multi, title = {A multi-perspective narrative-based geovisualization dashboard for the 2020 US presidential election}, author = {Rao, Jinmeng and Chen, Kexin and Yang, Ellie Fan and Kruse, Jacob and Hudson, Kyler and Gao, Song}, journal = {Journal of Geovisualization and Spatial Analysis}, volume = {5}, pages = {1--15}, year = {2021}, publisher = {Springer International Publishing}, }








2020
-
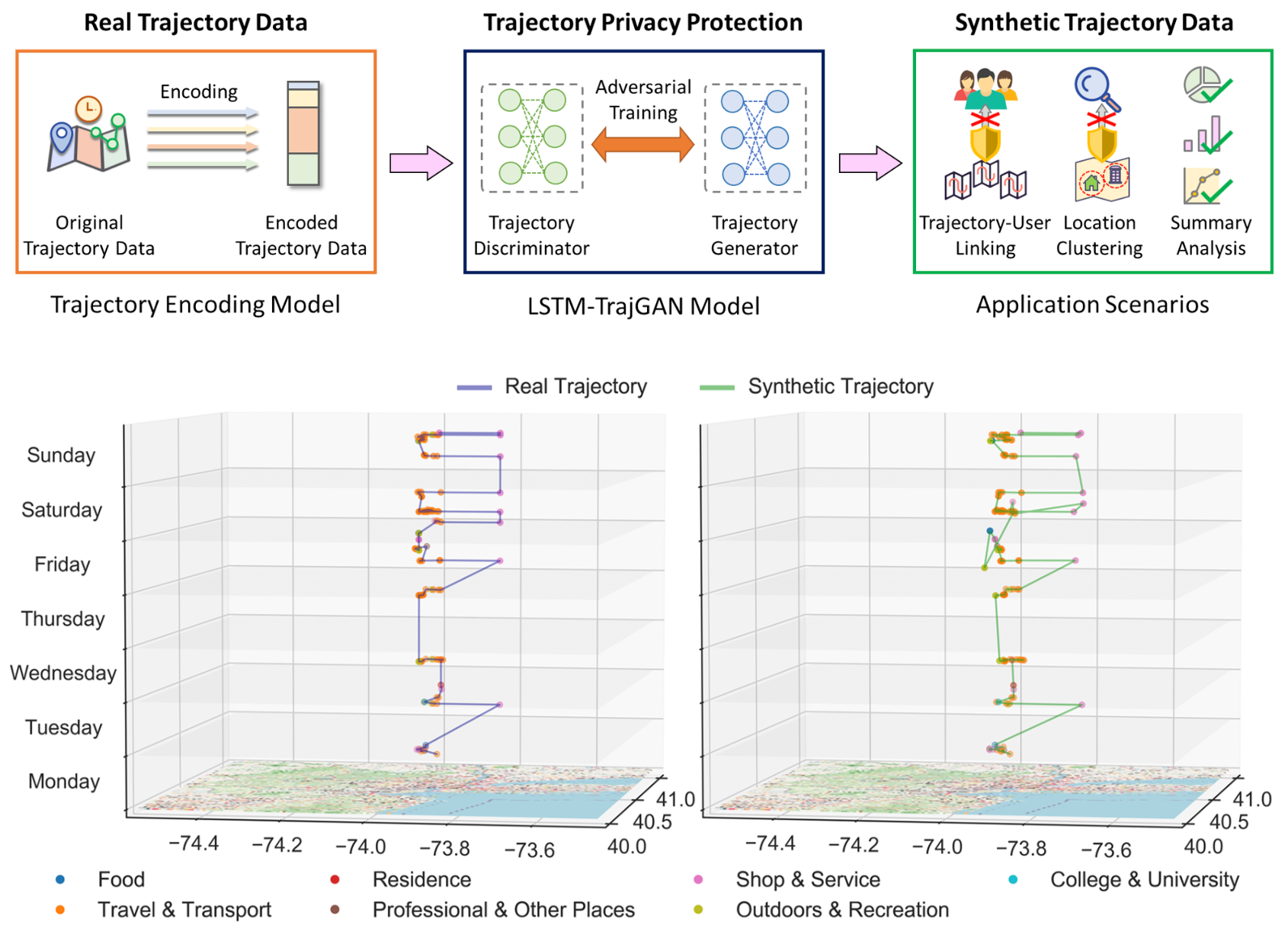 GISCIENCELSTM-TrajGAN: A deep learning approach to trajectory privacy protectionJinmeng Rao, Song Gao, Yuhao Kang, and Qunying HuangIn 11th International Conference on Geographic Information Science (GIScience 2021) - Part I, 2020Highlight: Top Conference in Geographic Information Sciences; Acceptance rate 34%
GISCIENCELSTM-TrajGAN: A deep learning approach to trajectory privacy protectionJinmeng Rao, Song Gao, Yuhao Kang, and Qunying HuangIn 11th International Conference on Geographic Information Science (GIScience 2021) - Part I, 2020Highlight: Top Conference in Geographic Information Sciences; Acceptance rate 34%The prevalence of location-based services contributes to the explosive growth of individual-level location trajectory data and raises public concerns about privacy issues. In this research, we propose a novel LSTM-TrajGAN approach, which is an end-to-end deep learning model to generate privacy-preserving synthetic trajectory data for data sharing and publication. We design a loss metric function TrajLoss to measure the trajectory similarity losses for model training and optimization. The model is evaluated on the trajectory-user-linking task on a real-world semantic trajectory dataset. Compared with other common geomasking methods, our model can better prevent users from being re-identified, and it also preserves essential spatial, temporal, and thematic characteristics of the real trajectory data. The model better balances the effectiveness of trajectory privacy protection and the utility for spatial and temporal analyses, which offers new insights into the GeoAI-powered privacy protection for human mobility studies.
@inproceedings{rao2020lstm, title = {LSTM-TrajGAN: A deep learning approach to trajectory privacy protection}, author = {Rao, Jinmeng and Gao, Song and Kang, Yuhao and Huang, Qunying}, booktitle = {11th International Conference on Geographic Information Science (GIScience 2021) - Part I}, volume = {177}, pages = {12--1}, year = {2020}, organization = {Schloss Dagstuhl--Leibniz-Zentrum f$\{$$\backslash$"u$\}$r Informatik}, note = {Highlight: Top Conference in Geographic Information Sciences; Acceptance rate 34\%}, } -
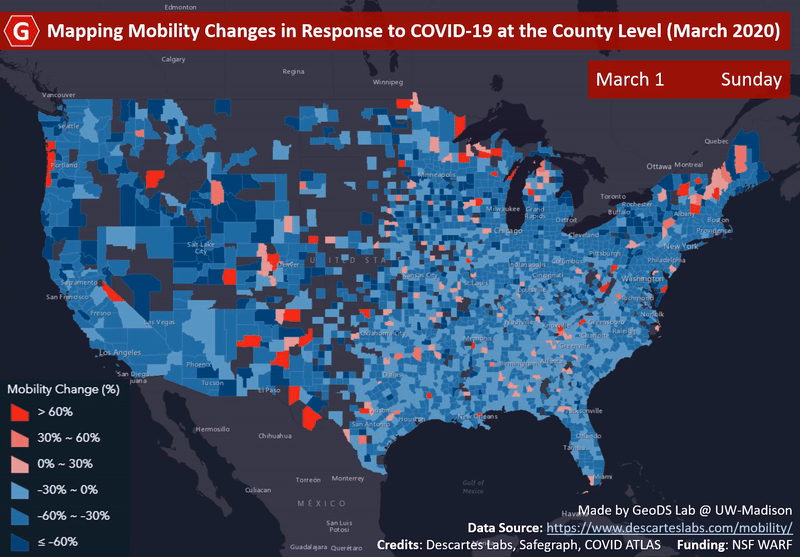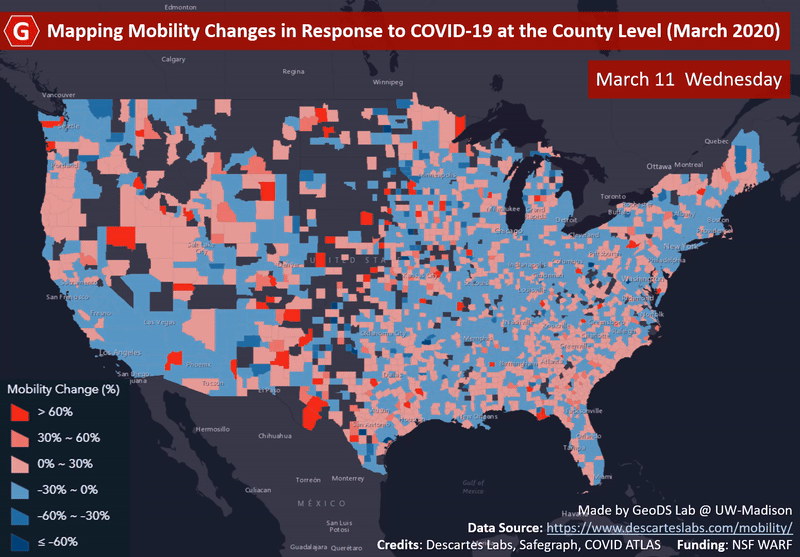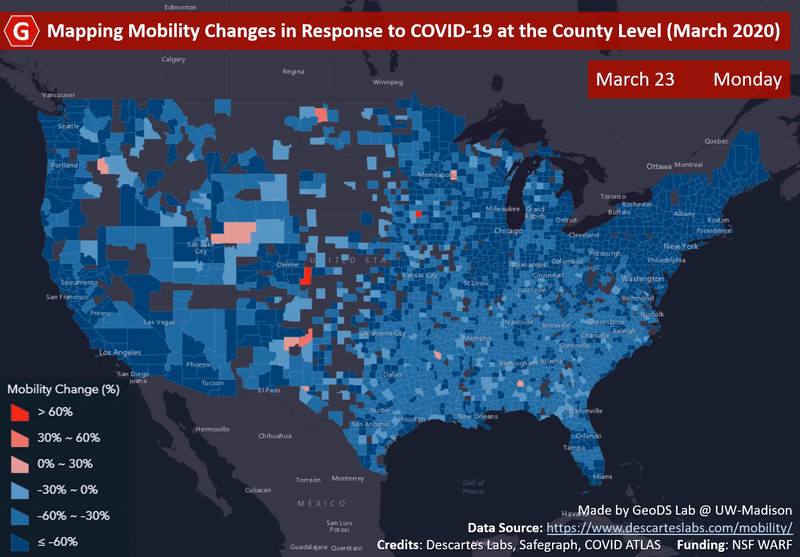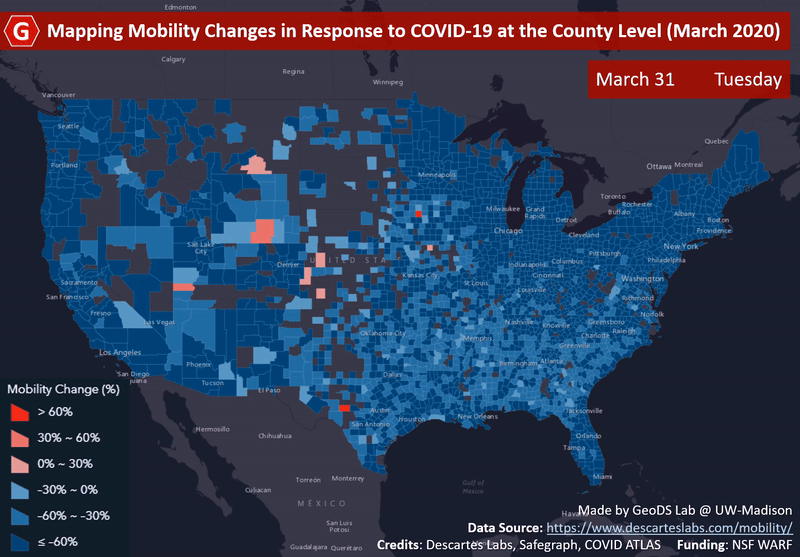 ACM SIGSPATIALMapping county-level mobility pattern changes in the United States in response to COVID-19Song Gao, Jinmeng Rao, Yuhao Kang, Yunlei Liang, and Jake KruseSIGSpatial Special, 2020Highlight: The first work on social distancing mapping during COVID-19; Media Coverage NBC, FOX, ABC
ACM SIGSPATIALMapping county-level mobility pattern changes in the United States in response to COVID-19Song Gao, Jinmeng Rao, Yuhao Kang, Yunlei Liang, and Jake KruseSIGSpatial Special, 2020Highlight: The first work on social distancing mapping during COVID-19; Media Coverage NBC, FOX, ABCTo contain the COVID-19 epidemic, one of the non-pharmacological epidemic control measures is reducing the transmission rate of SARS-COV-2 in the population through social distancing. An interactive web-based mapping platform that provides timely quantitative information on how people in different counties and states reacted to the social distancing guidelines was developed by the GeoDS Lab @UW-Madison with the support of the National Science Foundation RAPID program. The web portal integrates geographic information systems (GIS) and daily updated human mobility statistical patterns (median travel distance and stay-at-home dwell time) derived from large-scale anonymized and aggregated smartphone location big data at the county-level in the United States, and aims to increase risk awareness of the public, support data-driven public health and governmental decision-making, and help enhance community responses to the COVID-19 pandemic.
@article{gao2020mapping, title = {Mapping county-level mobility pattern changes in the United States in response to COVID-19}, author = {Gao, Song and Rao, Jinmeng and Kang, Yuhao and Liang, Yunlei and Kruse, Jake}, journal = {SIGSpatial Special}, volume = {12}, number = {1}, pages = {16--26}, year = {2020}, publisher = {ACM New York, NY, USA}, note = {Highlight: The first work on social distancing mapping during COVID-19; Media Coverage <a href="https://www.nbc15.com/2020/10/07/tracking-movement-in-wisconsin-leading-up-to-latest-health-order/">NBC</a>, <a href="http://fox47.com/news/local/uw-madison-researchers-map-travel-data-to-combat-pandemic">FOX</a>, <a href="https://www.wisn.com/article/uw-madison-scientists-develop-social-distancing-tracker-map/32163419#">ABC</a>}, } -
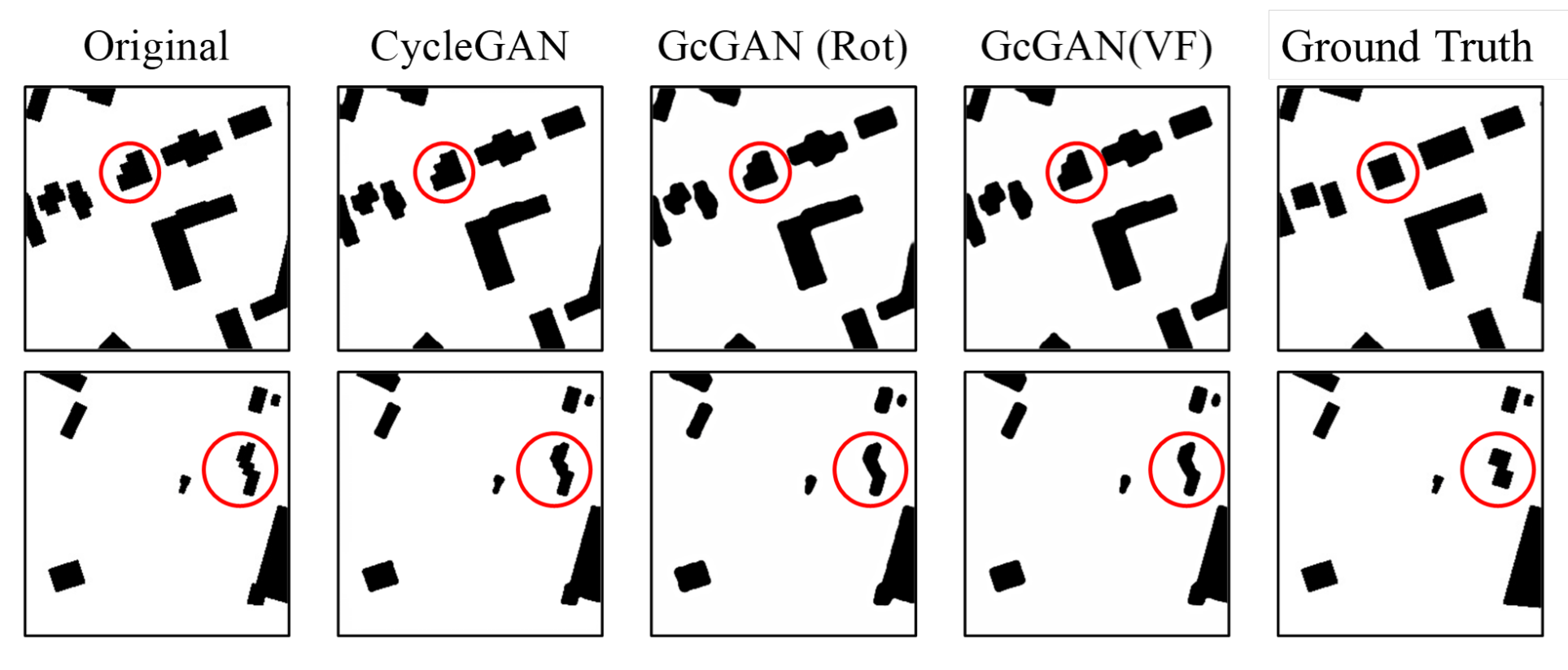 AUTOCARTOTowards cartographic knowledge encoding with deep learning: A case study of building generalizationY Kang, J Rao, W Wang, B Peng, S Gao, and F ZhangIn Proceedings of the AutoCarto, 2020
AUTOCARTOTowards cartographic knowledge encoding with deep learning: A case study of building generalizationY Kang, J Rao, W Wang, B Peng, S Gao, and F ZhangIn Proceedings of the AutoCarto, 2020@inproceedings{kang2020towards, title = {Towards cartographic knowledge encoding with deep learning: A case study of building generalization}, author = {Kang, Y and Rao, J and Wang, W and Peng, B and Gao, S and Zhang, F}, booktitle = {Proceedings of the AutoCarto}, year = {2020}, } -
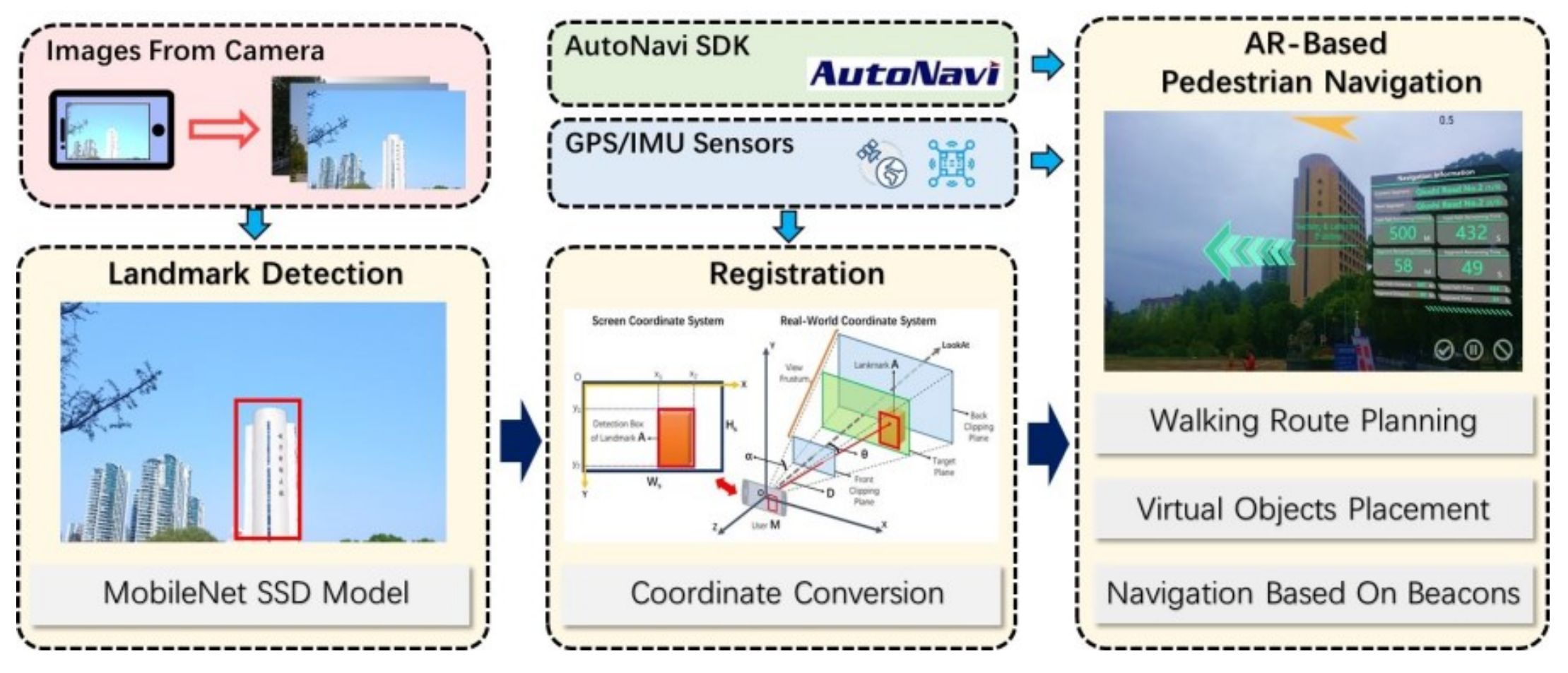 AUTOCARTOLandmarks as Beacons: Pedestrian Navigation Based on Landmark Detection and Mobile Augmented RealityJ Rao, S Gao, Y Kang, and Q DuIn Proceedings of the AutoCarto, 2020
AUTOCARTOLandmarks as Beacons: Pedestrian Navigation Based on Landmark Detection and Mobile Augmented RealityJ Rao, S Gao, Y Kang, and Q DuIn Proceedings of the AutoCarto, 2020@inproceedings{rao2020landmarks, title = {Landmarks as Beacons: Pedestrian Navigation Based on Landmark Detection and Mobile Augmented Reality}, author = {Rao, J and Gao, S and Kang, Y and Du, Q}, booktitle = {Proceedings of the AutoCarto}, year = {2020}, } -
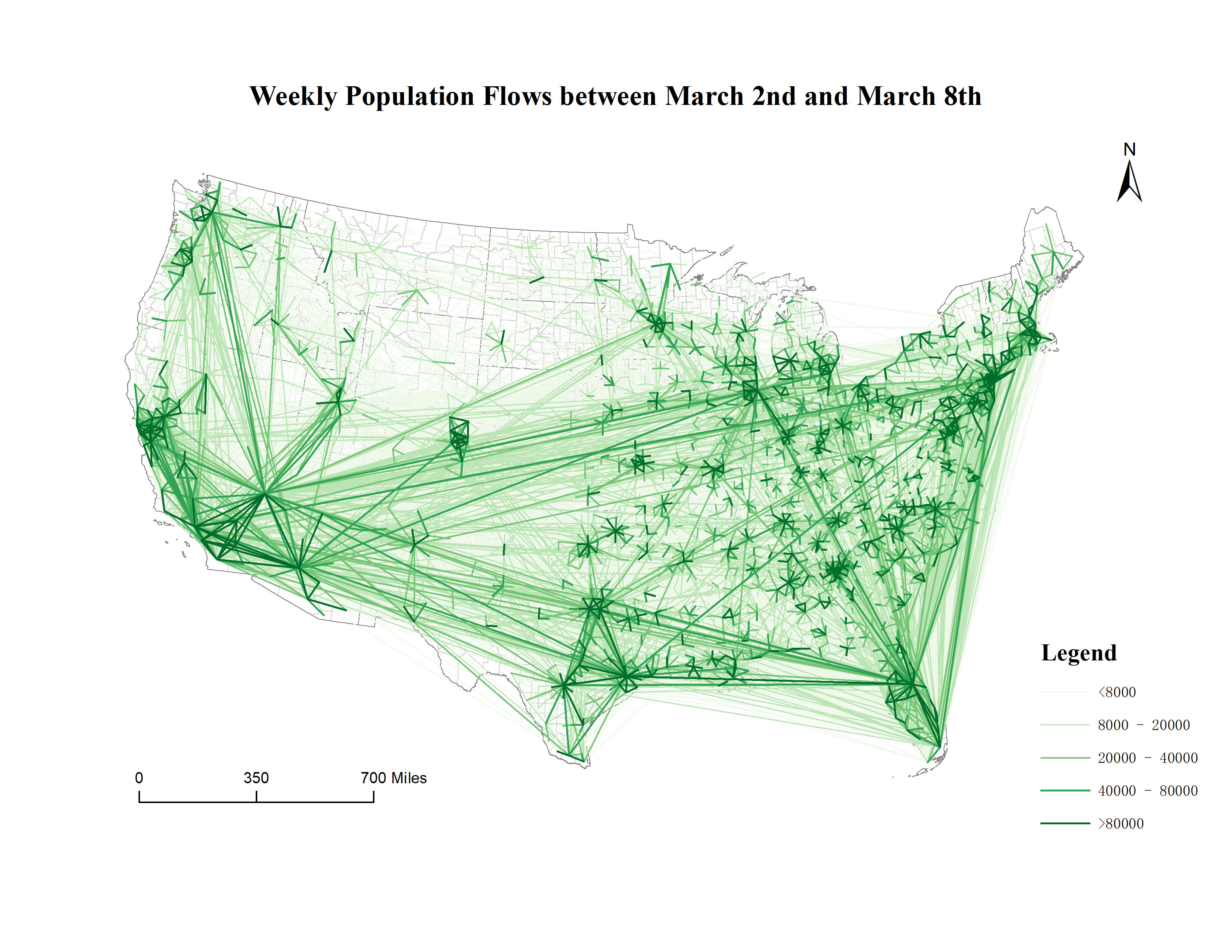 SCIENTIFIC DATAMultiscale dynamic human mobility flow dataset in the US during the COVID-19 epidemicYuhao Kang, Song Gao, Yunlei Liang, Mingxiao Li, Jinmeng Rao, and Jake KruseScientific data, 2020
SCIENTIFIC DATAMultiscale dynamic human mobility flow dataset in the US during the COVID-19 epidemicYuhao Kang, Song Gao, Yunlei Liang, Mingxiao Li, Jinmeng Rao, and Jake KruseScientific data, 2020Understanding dynamic human mobility changes and spatial interaction patterns at different geographic scales is crucial for assessing the impacts of non-pharmaceutical interventions (such as stay-at-home orders) during the COVID-19 pandemic. In this data descriptor, we introduce a regularly-updated multiscale dynamic human mobility flow dataset across the United States, with data starting from March 1st, 2020. By analysing millions of anonymous mobile phone users’ visits to various places provided by SafeGraph, the daily and weekly dynamic origin-to-destination (O-D) population flows are computed, aggregated, and inferred at three geographic scales: census tract, county, and state. There is high correlation between our mobility flow dataset and openly available data sources, which shows the reliability of the produced data. Such a high spatiotemporal resolution human mobility flow dataset at different geographic scales over time may help monitor epidemic spreading dynamics, inform public health policy, and deepen our understanding of human behaviour changes under the unprecedented public health crisis. This up-to-date O-D flow open data can support many other social sensing and transportation applications.
@article{kang2020multiscale, title = {Multiscale dynamic human mobility flow dataset in the US during the COVID-19 epidemic}, author = {Kang, Yuhao and Gao, Song and Liang, Yunlei and Li, Mingxiao and Rao, Jinmeng and Kruse, Jake}, journal = {Scientific data}, volume = {7}, number = {1}, pages = {390}, year = {2020}, publisher = {Nature Publishing Group UK London}, } -
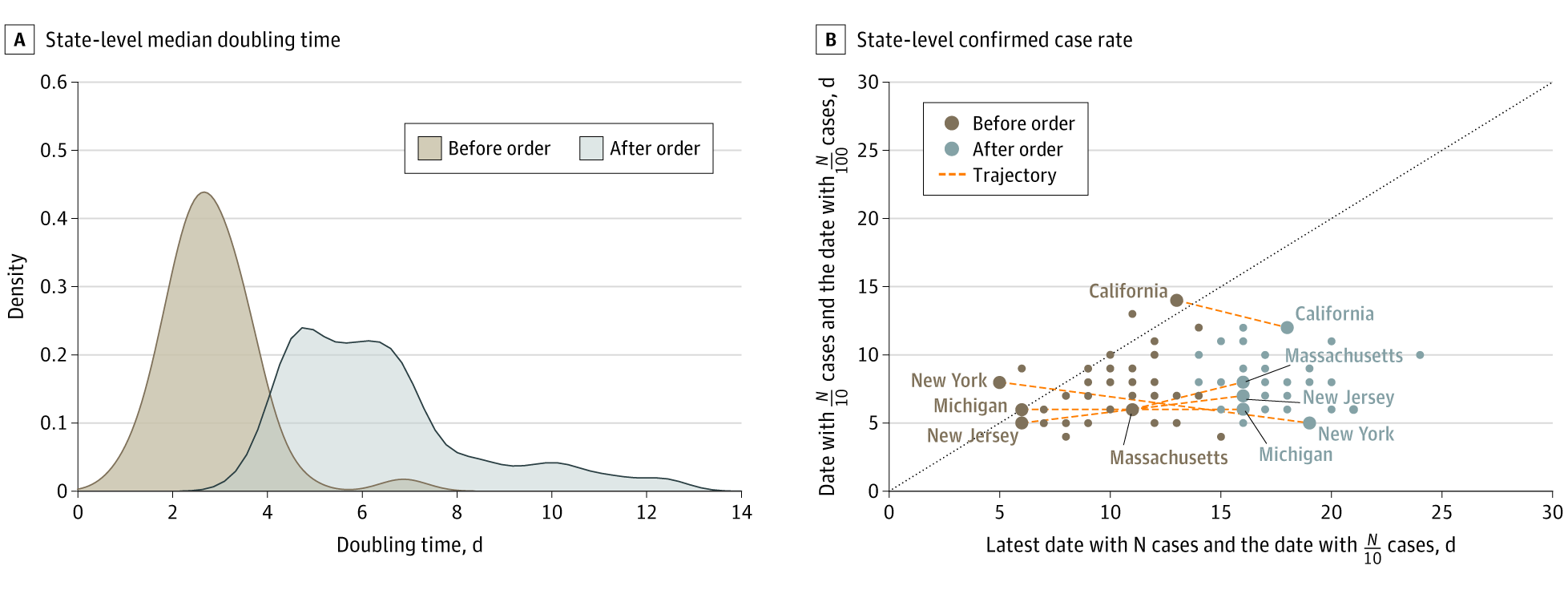 JAMAAssociation of mobile phone location data indications of travel and stay-at-home mandates with covid-19 infection rates in the usSong Gao, Jinmeng Rao, Yuhao Kang, Yunlei Liang, Jake Kruse, Dorte Dopfer, Ajay K Sethi, Juan Francisco Mandujano Reyes, Brian S Yandell, and Jonathan A PatzJAMA network open, 2020
JAMAAssociation of mobile phone location data indications of travel and stay-at-home mandates with covid-19 infection rates in the usSong Gao, Jinmeng Rao, Yuhao Kang, Yunlei Liang, Jake Kruse, Dorte Dopfer, Ajay K Sethi, Juan Francisco Mandujano Reyes, Brian S Yandell, and Jonathan A PatzJAMA network open, 2020Importance A stay-at-home social distancing mandate is a key nonpharmacological measure to reduce the transmission rate of severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2), but a high rate of adherence is needed. Objective To examine the association between the rate of human mobility changes and the rate of confirmed cases of SARS-CoV-2 infection. Design, Setting, and Participants This cross-sectional study used daily travel distance and home dwell time derived from millions of anonymous mobile phone location data from March 11 to April 10, 2020, provided by the Descartes Labs and SafeGraph to quantify the degree to which social distancing mandates were followed in the 50 US states and District of Columbia and the association of mobility changes with rates of coronavirus disease 2019 (COVID-19) cases. Exposure State-level stay-at-home orders during the COVID-19 pandemic. Main Outcomes and Measures The main outcome was the association of state-specific rates of COVID-19 confirmed cases with the change rates of median travel distance and median home dwell time of anonymous mobile phone users. The increase rates are measured by the exponent in curve fitting of the COVID-19 cumulative confirmed cases, while the mobility change (increase or decrease) rates were measured by the slope coefficient in curve fitting of median travel distance and median home dwell time for each state. Results Data from more than 45 million anonymous mobile phone devices were analyzed. The correlation between the COVID-19 increase rate and travel distance decrease rate was –0.586 (95% CI, –0.742 to –0.370) and the correlation between COVID-19 increase rate and home dwell time increase rate was 0.526 (95% CI, 0.293 to 0.700). Increases in state-specific doubling time of total cases ranged from 1.0 to 6.9 days (median [interquartile range], 2.7 [2.3-3.3] days) before stay-at-home orders were enacted to 3.7 to 30.3 days (median [interquartile range], 6.0 [4.8-7.1] days) after stay-at-home social distancing orders were put in place, consistent with pandemic modeling results. Conclusions and Relevance These findings suggest that stay-at-home social distancing mandates, when they were followed by measurable mobility changes, were associated with reduction in COVID-19 spread. These results come at a particularly critical period when US states are beginning to relax social distancing policies and reopen their economies. These findings support the efficacy of social distancing and could help inform future implementation of social distancing policies should they need to be reinstated during later periods of COVID-19 reemergence.
@article{gao2020association, title = {Association of mobile phone location data indications of travel and stay-at-home mandates with covid-19 infection rates in the us}, author = {Gao, Song and Rao, Jinmeng and Kang, Yuhao and Liang, Yunlei and Kruse, Jake and Dopfer, Dorte and Sethi, Ajay K and Reyes, Juan Francisco Mandujano and Yandell, Brian S and Patz, Jonathan A}, journal = {JAMA network open}, volume = {3}, number = {9}, pages = {e2020485--e2020485}, year = {2020}, publisher = {American Medical Association}, } -
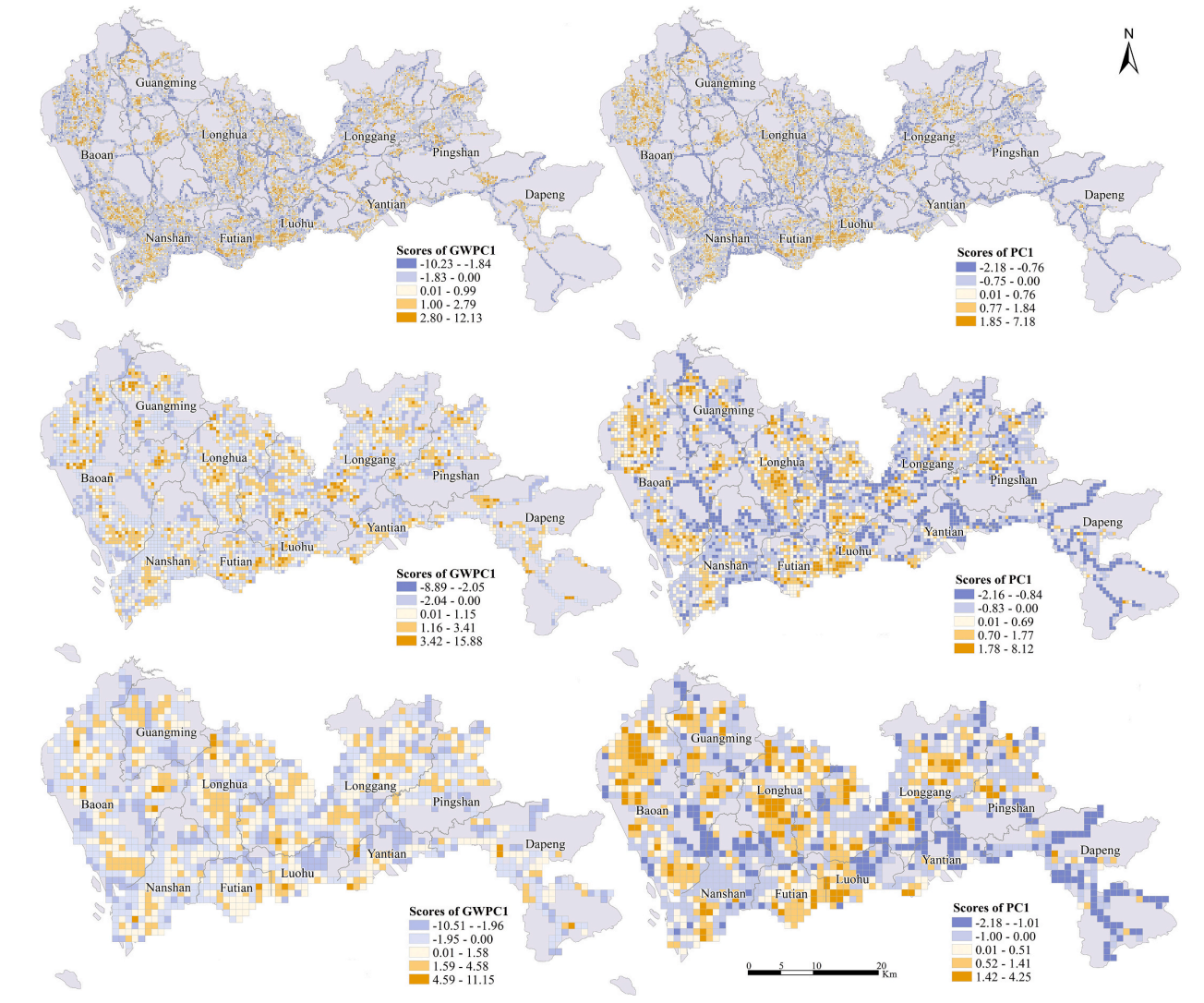 CEUSAssessing multiscale visual appearance characteristics of neighbourhoods using geographically weighted principal component analysis in Shenzhen, ChinaChao Wu, Ningyezi Peng, Xiangyuan Ma, Sheng Li, and Jinmeng Rao*Computers, Environment and Urban Systems, 2020
CEUSAssessing multiscale visual appearance characteristics of neighbourhoods using geographically weighted principal component analysis in Shenzhen, ChinaChao Wu, Ningyezi Peng, Xiangyuan Ma, Sheng Li, and Jinmeng Rao*Computers, Environment and Urban Systems, 2020The neighbourhood is a basic residential unit and is characterized by its physical setting, functional attributes and visual appearance. The visual appearance of a neighbourhood can directly affect the impression of humans regarding the local living environment. Assessing the characteristics of the visual appearance of a neighbourhood is significance for promoting people’s physical activities, improving residents’ sense of comfort and even ensuring the equality of facilities. However, studies assessing the spatial characteristics of visual appearance are still limited. Therefore, this article applies street view images to quantify the visual appearance of neighbourhoods at multiple scales in Shenzhen, China. Then, geographically weighted principal component analysis (GWPCA) is employed to explore the varying multivariate structures of visual appearance. The results confirm that GWPCA can be effective in assessing the visual appearance characteristics of neighbourhoods while considering spatial heterogeneity. The visual appearance characteristics of neighbourhoods are sensitive to both the spatial location and analysis scale. The extracted geographically weighted principal components (GWPCs) can represent the original screen elements by emphasizing certain comprehensive concepts, such as walkability, accessibility and vibrancy. The exploratory findings of this article allow for an improvement of studies on spatial quality at the human scale and could potentially guide neighbourhood planning and street design.
@article{wu2020assessing, title = {Assessing multiscale visual appearance characteristics of neighbourhoods using geographically weighted principal component analysis in Shenzhen, China}, author = {Wu, Chao and Peng, Ningyezi and Ma, Xiangyuan and Li, Sheng and Rao*, Jinmeng}, journal = {Computers, Environment and Urban Systems}, volume = {84}, pages = {101547}, year = {2020}, publisher = {Pergamon}, } -
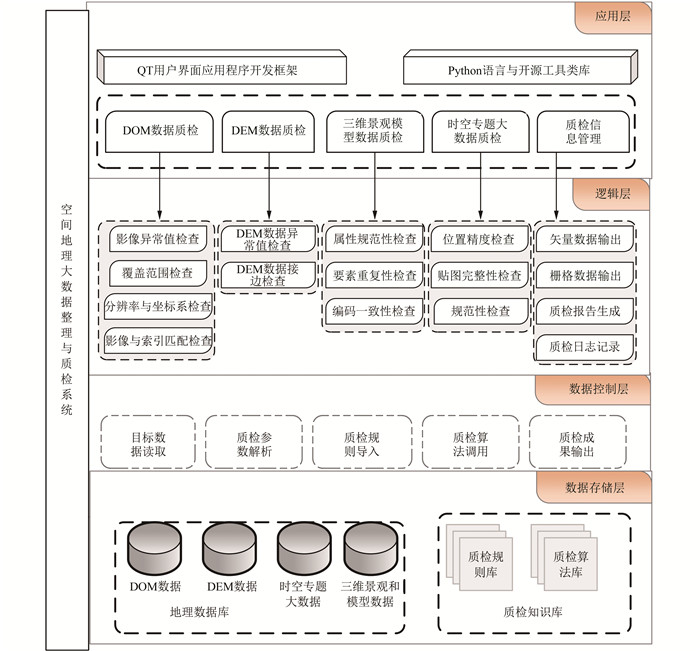 CHINESEMulti-source Geographic Data Efficient Quality Inspection System Based on PythonTian Du, Dalu Xu, Xiaojuan Zhu, Jinmeng Rao, and Qingyun Du2020
CHINESEMulti-source Geographic Data Efficient Quality Inspection System Based on PythonTian Du, Dalu Xu, Xiaojuan Zhu, Jinmeng Rao, and Qingyun Du2020For the ever-increasing massive geospatial big data and increasingly complex data quality inspection requirements, we design a comprehensive spatial data quality inspection system based on Python and QT framework. We use open source third-party tool libraries and independent research algorithms to process multiple types of spatial geographic big data, and combine with multi-process and multi-threading technology to improve quality inspection efficiency. The system uses the infrastructure development to achieve the indicator items of data quality inspection. The system can import flexible quality inspection rules, and export quality inspection logs and quality inspection results reports, and verify the feasibility, expandability and efficiency of the system in production practice.
@article{du2020geo, title = {Multi-source Geographic Data Efficient Quality Inspection System Based on Python}, author = {Du, Tian and Xu, Dalu and Zhu, Xiaojuan and Rao, Jinmeng and Du, Qingyun}, year = {2020}, publisher = {Journal of Geomatics}, }








2019
-
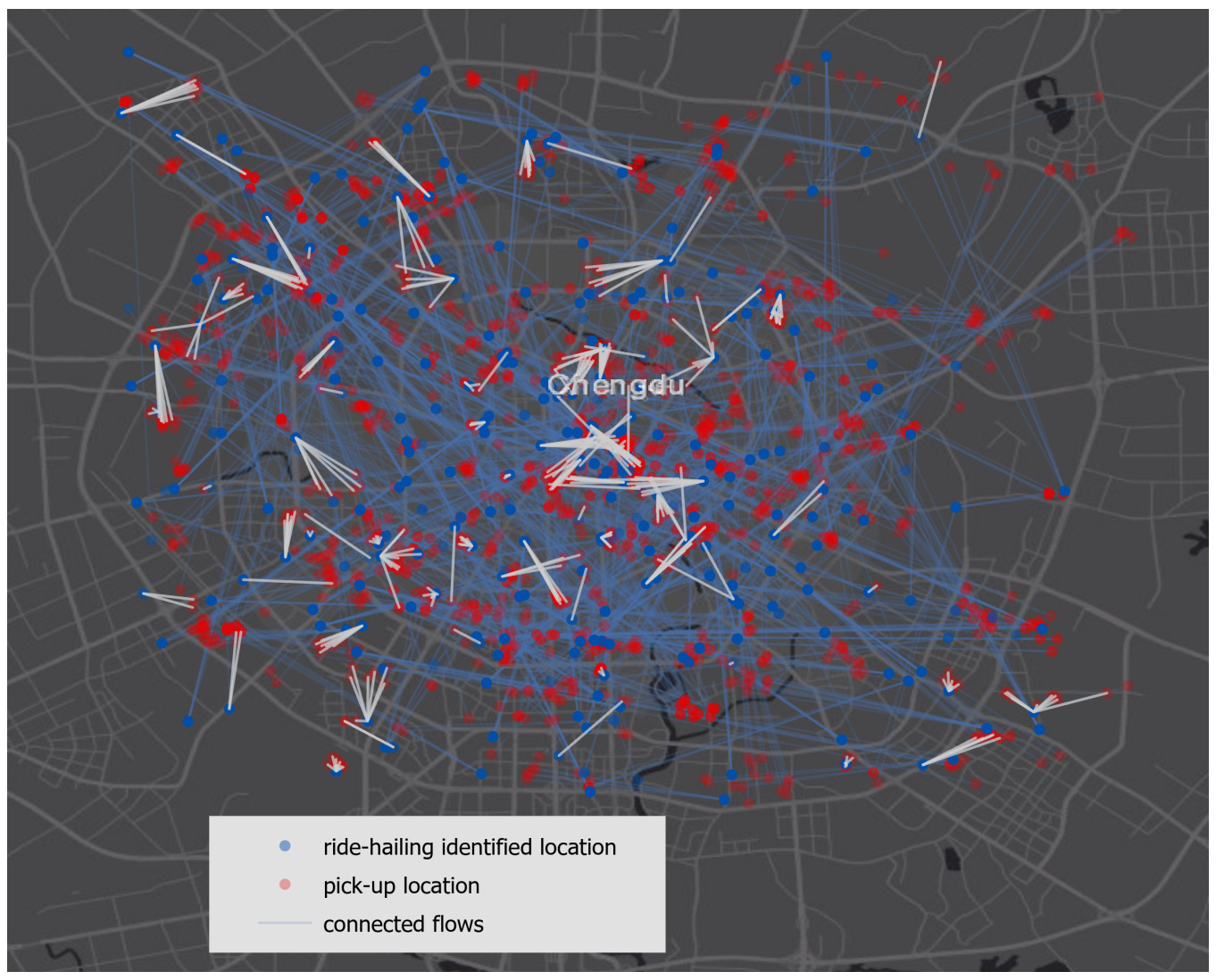 ACM SIGSPATIAL RAASAnalyzing the Gap Between Ride-hailing Location and Pick-up Location with Geographical ContextsYunlei Liang, Song Gao, Mingxiao Li, Yuhao Kang, and Jinmeng RaoIn Proceedings of the 1st ACM SIGSPATIAL International Workshop on Ride-hailing Algorithms, Applications, and Systems, 2019
ACM SIGSPATIAL RAASAnalyzing the Gap Between Ride-hailing Location and Pick-up Location with Geographical ContextsYunlei Liang, Song Gao, Mingxiao Li, Yuhao Kang, and Jinmeng RaoIn Proceedings of the 1st ACM SIGSPATIAL International Workshop on Ride-hailing Algorithms, Applications, and Systems, 2019Location uncertainty plays a key role in location-based services and applications. This research mainly focuses on the problem of location uncertainty when users are using the ride-hailing applications from the perspective of geographical contexts. The distance gap between the ride-hailing identified search location and the actual pick-up location was calculated and used as the measurement of location uncertainty. It may come from GPS noise or the gap between the current location of a passenger (eg, inside a building or a university campus) and the actual pick-up location along the streets for a ride. For the geographical contexts, this study considers factors including population density, road density, various kinds of Points Of Interests (POIs), and also the frequency of ride-hailing requests given a region. By using regression analysis techniques to find the relation between the geographical contexts and the distance gap, this study identifies potential factors (eg, enterprise buildings, dense roads, and highly populated areas) that affect the location uncertainty the most.
@inproceedings{liang2019analyzing, title = {Analyzing the Gap Between Ride-hailing Location and Pick-up Location with Geographical Contexts}, author = {Liang, Yunlei and Gao, Song and Li, Mingxiao and Kang, Yuhao and Rao, Jinmeng}, year = {2019}, booktitle = {Proceedings of the 1st ACM SIGSPATIAL International Workshop on Ride-hailing Algorithms, Applications, and Systems}, } -
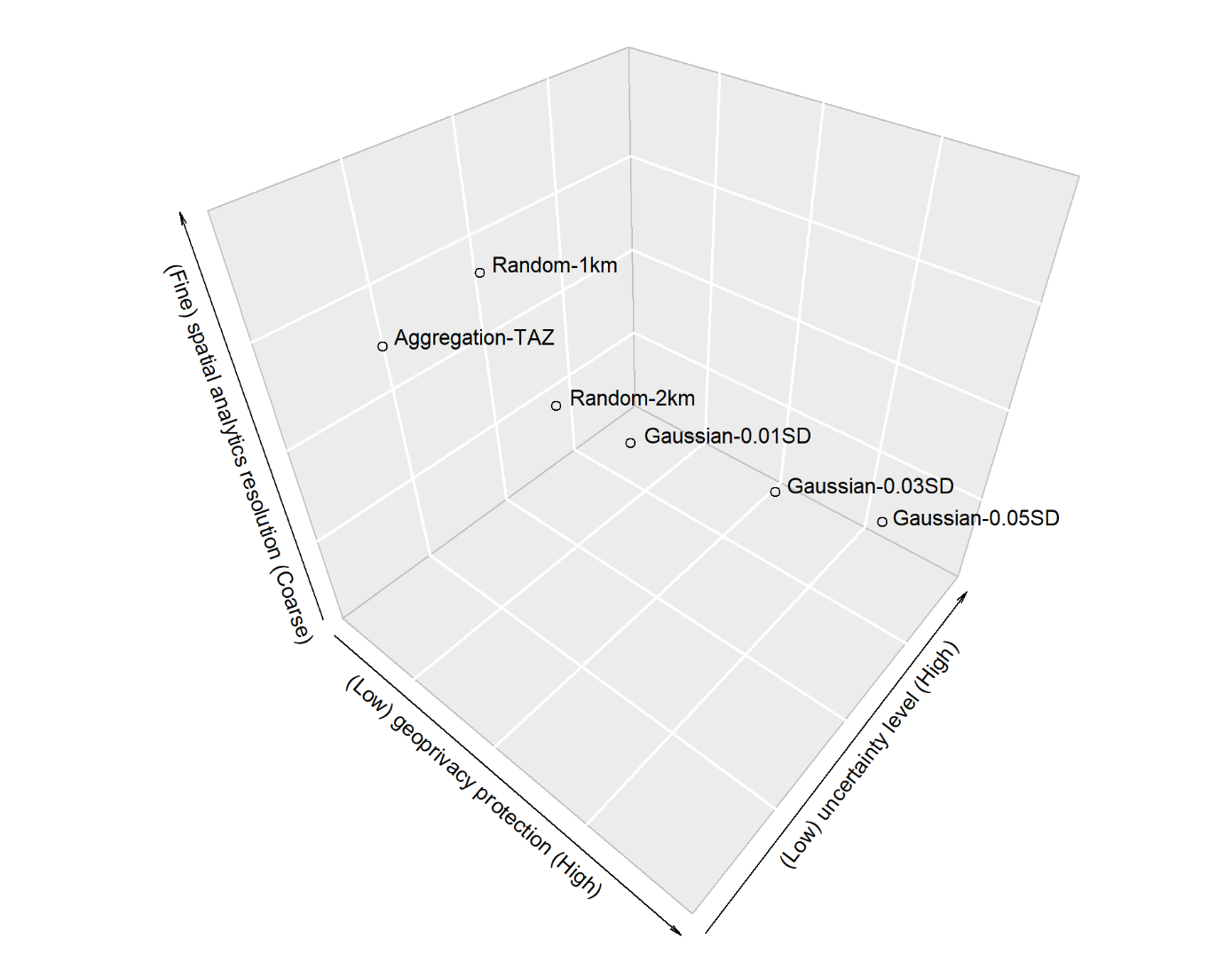 JOSISExploring the effectiveness of geomasking techniques for protecting the geoprivacy of Twitter usersSong Gao, Jinmeng Rao, Xinyi Liu, Yuhao Kang, Qunying Huang, and Joseph AppJournal of Spatial Information Science, 2019
JOSISExploring the effectiveness of geomasking techniques for protecting the geoprivacy of Twitter usersSong Gao, Jinmeng Rao, Xinyi Liu, Yuhao Kang, Qunying Huang, and Joseph AppJournal of Spatial Information Science, 2019With the ubiquitous use of location-based services, large-scale individual-level location data has been widely collected through location-awareness devices. Geoprivacy concerns arise on the issues of user identity de-anonymization and location exposure. In this work, we investigate the effectiveness of geomasking techniques for protecting the geoprivacy of active Twitter users who frequently share geotagged tweets in their home and work locations. By analyzing over 38,000 geotagged tweets of 93 active Twitter users in three U.S. cities, the two-dimensional Gaussian masking technique with proper standard deviation settings is found to be more effective to protect user’s location privacy while sacrificing geospatial analytical resolution than the random perturbation masking method and the aggregation on traffic analysis zones. Furthermore, a three-dimensional theoretical framework considering privacy, analytics, and uncertainty factors simultaneously is proposed to assess geomasking techniques. Our research offers insights into geoprivacy concerns of social media users’ georeferenced data sharing for future development of location-based applications and services.
@article{gao2019exploring, title = {Exploring the effectiveness of geomasking techniques for protecting the geoprivacy of Twitter users}, author = {Gao, Song and Rao, Jinmeng and Liu, Xinyi and Kang, Yuhao and Huang, Qunying and App, Joseph}, journal = {Journal of Spatial Information Science}, number = {19}, pages = {105--129}, year = {2019}, }


2017
-
 CHINESEGeographic Object Detection for Outdoor Augmented RealityYanjun Qiao, Jinmeng Rao, Junxing Wang, Qingyun Du, and Fu RenGeomatics World, 2017
CHINESEGeographic Object Detection for Outdoor Augmented RealityYanjun Qiao, Jinmeng Rao, Junxing Wang, Qingyun Du, and Fu RenGeomatics World, 2017This paper studies the convolutional neural network model for image classification and object detection in the field of computer vision, and modifies an object detection model which combines Res Net structures to solve the problem of geographic object detection in outdoor augmented reality. An outdoor augmented reality system is developed with the use of the proposed model trained as an object detection engine, which achieves the near-real-time performance and high accuracy.
@article{qiao2017outdoorar, title = {Geographic Object Detection for Outdoor Augmented Reality}, author = {Qiao, Yanjun and Rao, Jinmeng and Wang, Junxing and Du, Qingyun and Ren, Fu}, journal = {Geomatics World}, volume = {24}, number = {5}, pages = {51--55}, year = {2017}, } -
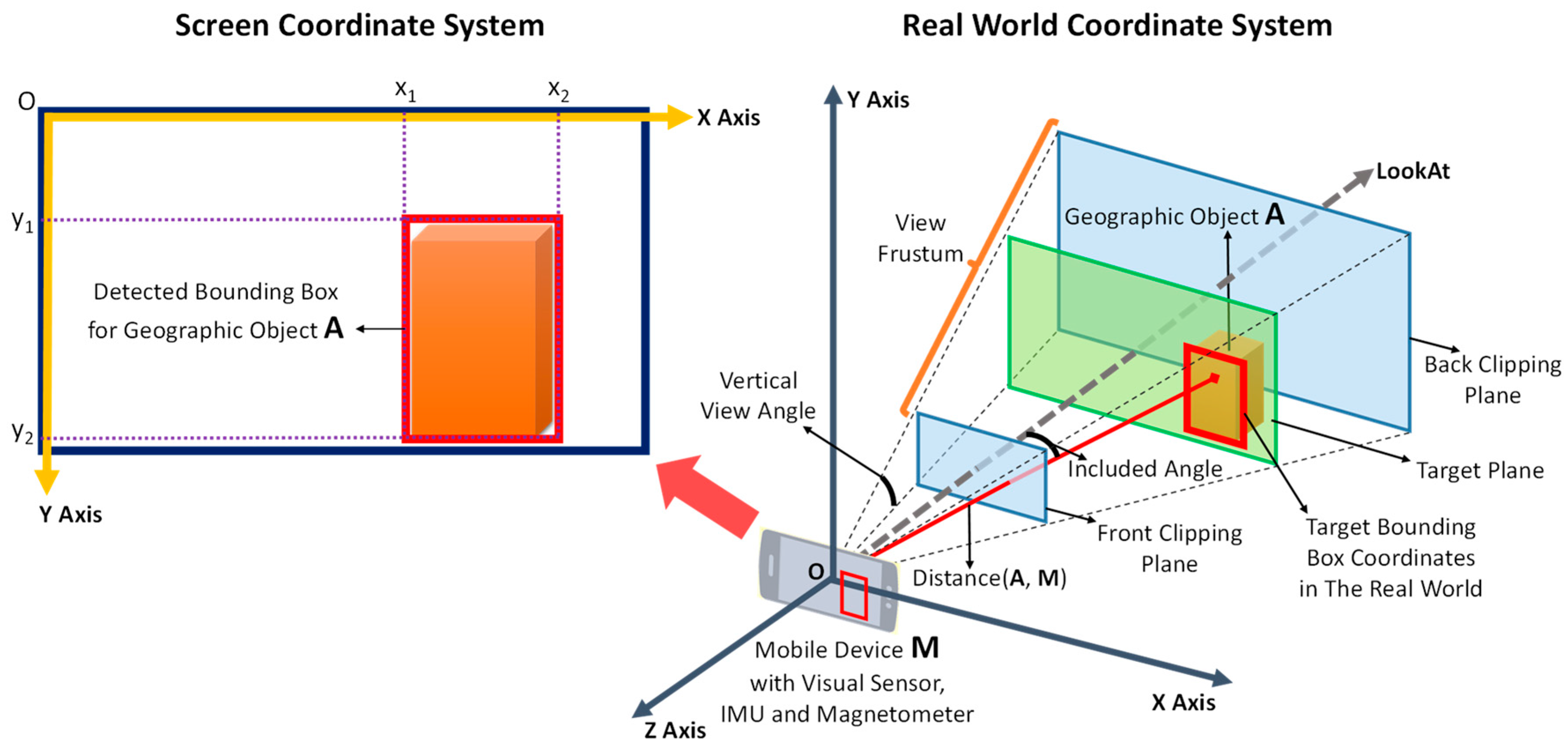 SENSORSA mobile outdoor augmented reality method combining deep learning object detection and spatial relationships for geovisualizationJinmeng Rao, Yanjun Qiao, Fu Ren, Junxing Wang, and Qingyun DuSensors, 2017
SENSORSA mobile outdoor augmented reality method combining deep learning object detection and spatial relationships for geovisualizationJinmeng Rao, Yanjun Qiao, Fu Ren, Junxing Wang, and Qingyun DuSensors, 2017The purpose of this study was to develop a robust, fast and markerless mobile augmented reality method for registration, geovisualization and interaction in uncontrolled outdoor environments. We propose a lightweight deep-learning-based object detection approach for mobile or embedded devices; the vision-based detection results of this approach are combined with spatial relationships by means of the host device’s built-in Global Positioning System receiver, Inertial Measurement Unit and magnetometer. Virtual objects generated based on geospatial information are precisely registered in the real world, and an interaction method based on touch gestures is implemented. The entire method is independent of the network to ensure robustness to poor signal conditions. A prototype system was developed and tested on the Wuhan University campus to evaluate the method and validate its results. The findings demonstrate that our method achieves a high detection accuracy, stable geovisualization results and interaction.
@article{rao2017mobile, title = {A mobile outdoor augmented reality method combining deep learning object detection and spatial relationships for geovisualization}, author = {Rao, Jinmeng and Qiao, Yanjun and Ren, Fu and Wang, Junxing and Du, Qingyun}, journal = {Sensors}, volume = {17}, number = {9}, pages = {1951}, year = {2017}, publisher = {MDPI}, }

